一文看懂C语言
关键字
关键字是语言规范中规定的,不能作为标识符使用,C 语言中的所有关键字(不带下划线的共 32 个)如下表所示。
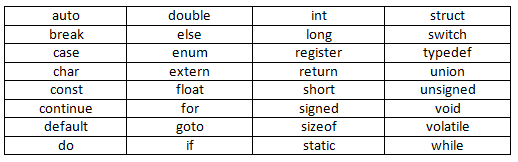
关键字分类
根据关键字的作用,可以将 32 个关键字分为数据类型关键字和流程控制关键字两大类。
数据类型关键字(20 个)
- 基本数据类型(5 个):void,char,int,float,double
- 数据类型修饰关键字(4 个):short,long,signed,unsigned
- 复杂类型关键字(5 个):struct,union,enum,typedef,sizeof
- 内存管理关键字(6 个):auto,static,register,extern,const,volatile
流程控制关键字(12 个)
- 跳转结构(4 个):return,continue,break,goto
- 分支结构(5 个):if,else,switch,case,default
- 循环结构(3 个):for,do,while
数据类型
| 名称 | 大小 | 描述 |
|---|---|---|
| char | 1 byte | 一个字符,如果是字符串则使用 char[] |
| short | 2 bytes | 带符号和不带符号两种 |
| int / long | 4 bytes | 带符号整数 |
| long long | 8 bytes | 更大的带符号整数 |
| float | 4 bytes | 单精度浮点数 |
| double | 8 bytes | 双精度浮点数 |
字符类型
字符常量必须放在单引号里面。
C 语言的字符是以整数形式存储的,每个字符都对应一个唯一的整数值。这种映射关系被称作美国信息交换标准代码(American Standard Code for Information Interchange,ASCII)。 字符类型的长度是一个字节,在不同计算机的默认范围是不一样的。一些系统默认为-128 到 127,另一些系统默认为 0 到 255。这两种范围正好都能覆盖 0 到 127 的 ASCII 字符范围。
只要在字符类型的范围之内,整数与字符是可以互换的,都可以赋值给字符类型的变量。因此,两个字符类型的变量可以进行数学运算。
1
2
3
4
char a = 66; // 等同于 char a = 'B';
char b = 'C'; // 等同于 char b = 67;
printf("%d\n", a + b); // 输出 133
在 C 语言中,为了方便,一些常用的特殊字符可以使用助记字母来代替它们的数值。这些字符可以使用斜杠加助记字母来表示。但是,并非所有的 ASCII 码中的不可见字符都有助记字母来代替它们的数值,因此在需要使用这些字符时,你可能需要查阅 ASCII 码表来获取它们对应的数值。
| 助记字母 | 数值 | 含义 |
|---|---|---|
| \n | 10 | 换行 |
| \t | 9 | 制表符 |
| \r | 13 | 回车 |
| \b | 8 | 退格 |
| \f | 12 | 换页 |
| \v | 11 | 垂直制表符 |
| \a | 7 | 报警 |
整数类型
不同计算机的 int 类型的大小是不一样的。比较常见的是使用 4 个字节(32 位)存储一个 int 类型的值。
整数的子类型
如果 int 类型使用 4 个或 8 个字节表示一个整数,对于小整数,这样做很浪费空间。另一方面,某些场合需要更大的整数,8 个字节还不够。为了解决这些问题,C 语言在 int 类型之外,又提供了三个整数的子类型。这样有利于更精细地限定整数变量的范围,也有利于更好地表达代码的意图。
- short int(简写为 short):占用空间不多于 int,一般占用 2 个字节(整数范围为-32768 ~ 32767)。
- long int(简写为 long):占用空间不少于 int,至少为 4 个字节。
- long long int(简写为 long long):占用空间多于 long,至少为 8 个字节。
不同的计算机,数据类型的字节长度是不一样的,
- 确实需要 32 位整数时,应使用 long 类型而不是 int 类型,可以确保不少于 4 个字节;
- 确实需要 64 位的整数时,应该使用 long long 类型,可以确保不少于 8 个字节。
另一方面,为了节省空间,
- 只需要 16 位整数时,应使用 short 类型;
- 只需要 8 位整数时,应该使用 char 类型。
unsigned 关键字
如果确定不会用到负数,则建议使用 unsigned 关键字,表明该数据类型不带有符号位。由于不带符号位,原本留给符号位的二进制位可用来表示数值,因此可以有效地表示比有符号整型更大的值。
| 类型 | 字节数 | 范围 |
|---|---|---|
| char | 1 | -128 ~ 127 |
| unsigned char | 1 | 0 ~ 255 |
| short | 2 | -32768 ~ 32767 |
| unsigned short | 2 | 0 ~ 65535 |
| int | 4 | -2147483648 ~ 2147483647 |
| unsigned int | 4 | 0 ~ 4294967295 |
整数类型的极限值
有时候需要查看,当前系统不同整数类型的最大值和最小值,C 语言的头文件 limits.h 提供了相应的常量,比如 SCHAR_MIN 代表 signed char 类型的最小值-128,SHRT_MAX 代表 short 类型的最大值 32767。 为了代码的可移植性,需要知道某种整数类型的极限值时,应该尽量使用这些常量。
| 常量 | 含义 |
|---|---|
| SCHAR_MIN | signed char 类型的最小值 |
| SCHAR_MAX | signed char 类型的最大值 |
| INT_MIN | int 类型的最小值 |
| INT_MAX | int 类型的最大值 |
整数的进制
C 语言的整数默认都是十进制数,如果要表示八进制数和十六进制数,必须使用专门的表示法。
- 八进制使用 0 作为前缀,比如 017、0377
- 十六进制使用 0x 或 0X 作为前缀,比如 0xf、0X10
- 有些编译器使用 0b 前缀,表示二进制数,但不是标准,比如 0b101010
不同的进制只是整数的书写方法,不会对整数的实际存储方式产生影响。所有整数都是二进制形式存储,跟书写方式无关。不同进制可以混合使用,比如10 + 015 + 0x20是一个合法的表达式。
浮点数类型
任何有小数点的数值,都会被编译器解释为浮点数。所谓浮点数就是使用$m\times b^e$的形式,存储一个数值,m 是小数部分,b 是基数(通常是 2),e 是指数部分。这种形式是精度和数值范围的一种结合,可以表示非常大或者非常小的数。
float 类型占用 4 个字节(32 位),其中 8 位存放指数的值和符号,剩下 24 位存放小数的值和符号。float 类型至少能够提供(十进制的)6 位有效数字,指数部分的范围为(十进制的)-37 到 37,即数值范围为 10-37到 1037。
有时候,32 位浮点数提供的精度或者数值范围还不够,C 语言又提供了另外两种更大的浮点数类型。
- double:占用 8 个字节(64 位),至少提供 13 位有效数字。
- long double:通常占用 16 个字节。
由于存在精度限制,浮点数只是一个近似值,它的计算是不精确的,比如 C 语言里面0.1 + 0.2并不等于0.3,而是有一个很小的误差。
1
if (0.1 + 0.2 == 0.3) // false
C 语言允许使用科学计数法表示浮点数,使用字母 e 来分隔小数部分和指数部分。另外,科学计数法的小数部分如果是 0.x 或 x.0 的形式,那么 0 可以省略。
1
2
3
4
double x = 123.456e+3; // 123.456 x 10^3,等同于 double x = 123.456e3;
0.3E6 // 等同于 .3E6
3.0E6 // 等同于 3.E6
布尔类型
C 语言原来并没有为布尔值单独设置一个类型,而是使用整数 0 表示伪,所有非零值表示真。 头文件stdbool.h定义了另一个类型别名 bool,并且定义了true代表 1、false代表 0。只要加载这个头文件,就可以使用这几个关键字。
1
2
#include <stdbool.h>
bool flag = false;
字面量类型
字面量(literal)指的是代码里面直接出现的值。
1
int x = 123; // x是变量,123就是字面量。
编译时,字面量也会写入内存,编译器会自动为字面量指定相应的数据类型,例如十进制整数的字面量(比如 123)会被编译器指定为 int 类型。
有时候,程序员希望为字面量指定一个不同的类型。比如,编译器将一个整数字面量指定为 int 类型,但是程序员希望将其指定为 long 类型,这时可以为该字面量加上后缀 l 或 L,编译器就知道要把这个字面量的类型指定为 long。
1
2
int x = 123L; // 字面量123有后缀L,编译器就会将其指定为long类型
int x = 123u; // 指定为无符号整数unsigned int
常用的字面量后缀有下面这些。
f和F:float 类型。l和L:对于整数是 long int 类型,对于小数是 long double 类型。ll和LL:Long Long 类型。u和U:表示 unsigned int。
类型转换
某些情况下,C 语言会自动转换某个值的类型。
- 赋值运算符会自动将右边的值,转成左边变量的类型。
- 不同类型的值进行混合计算时,必须先转成同一个类型,才能进行计算。
- 两个相同类型的整数运算时,宽度小于 int 的类型,运算结果会自动提升为 int。
- 函数的参数和返回值,会自动转成函数定义里指定的类型。
原则上,应该避免类型的自动转换,防止出现意料之外的结果。只要在一个值或变量的前面,使用圆括号指定类型,就可以将这个值或变量转为指定的类型,这叫做类型指定(casting)。
1
2
3
4
5
6
#include <stdio.h>
int main() {
int n1 = 5, n2 = 2;
printf("%f\n", (float)n1/n2); //强制类型转换
return 0;
}
数据溢出
每一种数据类型都有数值范围,如果存放的数值超出了这个范围,需要更多的二进制位存储,就会发生溢出。大于最大值,叫做向上溢出(overflow);小于最小值,叫做向下溢出(underflow)。
一般来说,编译器不会对溢出报错,会正常执行代码,但是会忽略多出来的二进制位,只保留剩下的位,这样往往会得到意想不到的结果。所以,应该避免溢出。
1
2
3
unsigned char x = 255;
x = x + 1;
printf("%d\n", x); // 输出结果为 0
为了避免溢出,最好方法就是将运算结果与类型的极限值进行比较。
1
2
3
4
5
6
7
8
9
10
unsigned int ui;
unsigned int sum;
// !!错误做法!!因为在进行加法时就有可能已经发生溢出
if (sum + ui > UINT_MAX) too_big();
else sum = sum + ui;
// 正确做法
if (ui > UINT_MAX - sum) too_big();
else sum = sum + ui;
可移植类型
C 语言的整数类型(short、int、long)在不同计算机上,占用的字节宽度可能是不一样的,无法提前知道它们到底占用多少个字节。
为了控制准确的字节宽度,确保代码可以有更好的可移植性,在头文件stdint.h中使用 typedef 命令创造了一些新的类型别名。
| 类型别名 | 含义 |
|---|---|
| int8_t | 8 位有符号整数 |
| int16_t | 16 位有符号整数 |
| int32_t | 32 位有符号整数 |
| int64_t | 64 位有符号整数 |
| uint8_t | 8 位无符号整数 |
| uint16_t | 16 位无符号整数 |
| uint32_t | 32 位无符号整数 |
| uint64_t | 64 位无符号整数 |
通过将整型类型用别名替代,不同架构的计算机只需修改这个头文件即可,而无需修改代码,这样可以避免由于不同平台上整型数据取值范围的差异而导致的数据溢出问题。
1
2
3
4
5
6
7
#include <stdio.h>
#include <stdint.h>
int main(void) {
int32_t x32 = 45933945; // 保证是32位的宽度
printf("x32 = %d\n", x32);
return 0;
}
typedef 命令
typedef 命令用来为某个类型起别名。
1
2
3
4
5
typedef unsigned char BYTE;
BYTE c = 'z';
typedef char* STRING;
STRING name;
typedef 也可以为指针、数组、结构体、函数起别名。
1
2
3
4
5
6
7
8
typedef int* intptr;
int a = 10;
intptr x = &a;
typedef int five_ints[5];
five_ints x = {11, 22, 33, 44, 55};
typedef signed char (*fp)(void);
typedef 为类型起别名的好处,主要有下面几点。
- 增强代码的可移植性,例如头文件
stdint.h定义的整形别名 - 增强代码的可读性
- 为 struct、union、enum 等命令定义的复杂数据结构创建别名,从而便于引用。
- typedef 方便以后为变量改类型
- 简化一些复杂的类型声明
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
struct Person {
char name[20];
int gender;
double height;
double weight;
};
//未使用typedef语句,声明一个结构体时需要加上struct
struct Person Timmy = {"timmy", 1, 170.00, 60.00};
typedef struct Person{
char name[20];
int gender;
double height;
double weight;
} Per;
//使用typedef语句,相当于#define Per struct Person,声明时只使用别名Per就可以
Per Timmy = {"timmy", 1, 170.00, 60.00};
运算符
| 名称 | 示例 | 描述 |
|---|---|---|
| +, -, *, /, %(取余) | 1+2 | 数学运算 |
| ++, – | ++i, –i, i++, i– | i 的位置会影响返回值 |
| ==, !=, <, >, <=, >= | 1 != 2 | 关系运算 |
| &&, ||, ! | a&&b | 逻辑运算 |
| &, |, ^, ~ | a&b | 位运算:与、或、异或、非 |
| », « | int n=10; n «2 | 位运算:左移 2 位后,n=40 |
| =, +=, -=, *= | a += 3 | 赋值运算符 |
| , | a, = b,c,d; | 逗号运算符,执行 b,c,d,且 a=d |
| ?: | (i > j) ? i : j; | 条件运算符,返回 i 和 j 的较大值 |
| & | &a | 指针运算符,取变量地址 |
| * | *a | 指针运算符,取变量值 |
| -> | ptr->name; | 成员间接运算符,访问结构体成员 |
| . | struct.name | 成员直接运算符,访问结构体成员 |
在 C 语言中,整型与整型进行运算的结果仍然是一个整型,结果的小数部分会被截断。为了得到正确的结果,我们需要将变量 a、b 和 c 都声明为浮点型。这样,a 和 b 进行的运算就是浮点型运算,结果也是浮点型。
运算优先级
当一个表达式中包含多个运算符时,会根据运算符的优先级来决定执行顺序。如果两个运算符优先级相同,则根据运算符是左结合,还是右结合,决定执行顺序。大部分运算符是左结合(从左到右执行),少数运算符是右结合(从右到左执行),比如赋值运算符(=)。
完全记住所有运算符的优先级没有必要,解决方法是多用圆括号,防止出现意料之外的情况,也有利于提高代码的可读性。
控制语句
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
// if语句
if (i > j) {
printf("i is greater than j\n");
} else {
printf("i is less than or equal to j\n");
}
// 条件运算符
(i > j) ? i : j;
// switch语句
switch (i) {
case 1:
printf("i is 1\n");
}
// for循环
for (i = 0; i < 10; i++) {
printf("i is %d\n", i);
}
// while循环
while (i < 10) {
printf("i is %d\n", i);
i++;
}
// do-while循环
do {
printf("i is %d\n", i);
i++;
} while (i < 10);
三个用于控制语句的关键字:
- break:提前结束循环
- continue:开始新一轮循环
- goto:无条件跳转语句,但是一般不建议使用 goto 语句,因为它使得程序的控制流难以跟踪,使程序难以理解和修改。
指针
内存地址是内存中每个数据单元的唯一标识符,因此计算机系统可以通过内存地址来访问内存中的数据。记录一个数据对象在内存中的存储位置需要以下两个信息。
- 数据对象的首地址。
- 数据对象占用的存储空间大小。
指针是什么?首先,它是一个值,这个值代表一个内存地址,因此指针相当于指向某个内存地址的路标。
字符*表示指针,通常跟在类型关键字的后面,表示指针指向的是什么类型的值。比如,char*表示一个指向字符的指针。
一般使用星号紧跟在类型关键字后面的写法,即int* intPtr;,因为这样可以体现,指针变量就是一个普通变量,只不过它的值是内存地址而已。这种写法有一个地方需要注意,即同一行声明两个指针变量。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
int* a; // a是一个整型指针
char* b; // b是一个字符指针
int* c[2]; // c是一个指针数组,包括两个指向整型的指针,等同于int *(c[2]);
int * foo, * bar; // 同一行声明两个指针变量的写法
int** foo; // 一个指针指向的可能还是指针
int* p[n]; //int *(p[n]),p为指针数组,由n个指向整型量的指针元素组成
int (*p)[n]; // p为指向整型数组的指针变量
int* p(); // p为返回指针值的函数,该指针指向整型量,p为函数名称
int (*p)(); // p为指向函数的指针,(*p)整体可以看作是函数名称,p代表函数的入口地址
// 访问成员操作符:(pointer_name)->(variable_name)
struct { int n; double root; } s[1]; // s是一个指向结构体的指针或长度为1的数组
s->root = sqrt(s->n = 7); // s->root 等同于 (*s).root 或 s[0].root
printf(“%g\n”, s->root);
取值运算符*:可以根据指针中存储的首地址和空间大小找到目标数据对象。
1
2
3
void increment(int* p) {
*p = *p + 1;
}
函数 increment()的参数是一个整数指针 p。函数体里面,p 就表示指针 p 所指向的那个值。对p 赋值,就表示改变指针所指向的那个地址里面的值。
变量地址而不是变量值传入函数,还有一个好处。对于需要大量存储空间的大型变量,复制变量值传入函数,非常浪费时间和空间,不如传入指针来得高效。
取地址运算符&:可以获取一个数据对象的首地址和所需的存储空间大小。
1
2
int x = 1;
printf("x's address is %p\n", &x); // %p是内存地址的占位符,可以打印出内存地址。
可以像下面这样使用 increment()函数:
1
2
3
int x = 1;
increment(&x);
printf("%d\n", x); // 输出结果:2
指针变量的初始化
声明指针变量之后,编译器会为指针变量本身分配一个内存空间,但是这个内存空间里面的值是随机的,也就是说,指针变量指向的值是随机的。这时一定不能去读写指针变量指向的地址,因为那个地址是随机地址,很可能会导致严重后果。
1
2
int* p;
*p = 1; // 错误,p指向的那个地址是随机的,向这个随机地址里面写入1,会导致意想不到的结果。
正确做法是指针变量声明后,必须先让它指向一个分配好的地址,然后再进行读写,这叫做指针变量的初始化。
1
2
3
4
int* p;
int i;
p = &i; //让p指向i的内存地址,完成初始化
*p = 13;
为了防止读写未初始化的指针变量,可以养成习惯,将未初始化的指针变量设为 NULL。
1
int* p = NULL;
NULL 是stdlib.h中定义的一个常量,表示地址为 0 的内存空间,这个地址是无法使用的,读写该地址会报错。
指针的运算
指针本质上就是一个无符号整数,代表了内存地址。它可以进行运算,但是规则并不是整数运算的规则。
指针与整数值的运算,表示指针的移动。指针移动的单位,与指针指向的数据类型有关。数据类型占据多少个字节,每单位就移动多少个字节。
1
2
3
short* j;
j = (short*)0x1234;
j = j + 1; // 0x1236
j 是一个指针,指向内存地址 0x1234。你可能以为 j + 1 等于 0x1235,但正确答案是 0x1236。原因是 j + 1 表示指针向内存地址的高位移动一个单位,而一个单位的 short 类型占据 2 个字节的宽度,所以相当于向高位移动 2 个字节。同样的,j - 1 得到的结果是 0x1232。
指针只能与整数值进行加减运算,两个指针进行加法是非法的。
相同类型的指针允许进行减法运算,返回它们之间的距离,即相隔多少个数据单位。返回的值属于ptrdiff_t类型,这是一个带符号的整数类型别名,具体类型根据系统不同而不同。这个类型的原型定义在头文件stddef.h里面。
- 高位地址减去低位地址,返回的是正值。
- 低位地址减去高位地址,返回的是负值。
1
2
3
4
5
6
7
short* j1;
short* j2;
j1 = (short*)0x1234;
j2 = (short*)0x1236;
ptrdiff_t dist = j2 - j1;
printf("%d\n", dist); // 输出结果:1
指针之间的比较运算,比较的是各自的内存地址哪一个更大,返回值是整数 1(true)或 0(false)。
指针和数组
声明数组时,数组名会被转换为一个指向数组第一个元素的指针,这意味着数组名的值是数组第一个元素的地址。
1
2
3
4
5
6
int a[10];
int* p;
int i = a[0]; // i是数组a的第一个元素
i = *a; // 取指针a的值,即数组a的第一个元素
p = a; // 将指针p指向数组a的第一个元素,等同于 p = &a[0]
p++; // 将指针p指向数组a的第二个元素,等同于 p = p+1; 也等同于 p = &a[1]; 也等同于 p = a+1
函数
return 语句给出函数的返回值,程序运行到这一行,就会跳出函数体,结束函数的调用。如果函数没有返回值,可以省略 return 语句,或者写成return;。没有返回值的函数,需要使用 void 关键字表示返回值的类型。同样,没有参数的函数,声明时也要用 void 关键字表示参数类型,main 函数是个例外,可以留空。
函数必须声明后使用,并且根据 C 语言标准规定,函数只能声明在源码文件的顶层,不能声明在其他函数内部。
1
2
3
int plus_one(int n) {
return n + 1;
}
main 函数
一个程序必须有一个main()函数,程序总是从这个函数开始执行,如果没有该函数,程序就无法启动。其他函数都是通过它引入程序的。main()函数返回值类型为 int,返回值为 0 代表程序正常结束。
1
2
3
4
int main() {
printf("Hello World\n");
return 0;
}
参数的传递
如果函数的参数是一个变量,那么调用该函数时,传入的是这个变量的值的拷贝,而不是变量本身,即值传递(pass by value)。所以,如果参数变量发生变化,最好把它作为返回值传出来。
1
2
3
4
5
6
7
void increment(int a) {
a++;
}
int i = 10;
increment(i);
printf("%d\n", i); // 结果:10
如果想要传入变量本身,就需要使用引用传递(pass by reference),即传入变量的地址(指针)。
1
2
3
4
5
6
7
8
9
10
void Swap(int* x, int* y) {
int temp;
temp = *x;
*x = *y;
*y = temp;
}
int a = 1;
int b = 2;
Swap(&a, &b);
注意,函数不要返回内部变量的指针。下面的示例中,函数返回内部变量i的指针,这种写法是错的。因为当函数结束运行时,内部变量就消失了,这时指向内部变量i的内存地址就是无效的,再去使用这个地址是非常危险的。
1
2
3
4
5
int* f(void) {
int i;
// ...
return &i;
}
函数指针
函数本身就是一段内存里面的代码,C 语言允许通过指针获取函数。通过函数指针也可以调用函数。
1
2
3
4
5
6
void print(int a) {
printf("%d\n", a);
}
void (*print_ptr)(int) = &print;
(*print_ptr)(10); // 等同于 print(10);
变量print_ptr是一个函数指针,它指向函数print()的地址。函数print()的地址可以用&print获得。注意,(*print_ptr)一定要写在圆括号里面,否则函数参数(int)的优先级高于*,整个式子就会变成void* print_ptr(int),表示返回一个返回值类型为任意类型的指针void*的函数。
比较特殊的是,C 语言还规定,函数名本身就是指向函数代码的指针,通过函数名就能获取函数地址。也就是说,print、*print和&print是一回事,因此上面的函数指针声明也可以写成下面的形式:
1
void (*print_ptr)(int) = print;
不过为了简洁易读,一般情况下,函数名前面都不加*和&,只有在一个函数是另一个函数的参数或返回值这种特殊情形下,函数前可以加*表明这个参数是一个函数如下面的函数原型所示:
1
int compute(int (*myfunc)(int), int, int);
作用域
C 语言共有三种作用域类型:块作用域、函数作用域和文件作用域。
- 块作用域
{}:指在代码块中定义的标识符的作用范围。这些标识符仅在它们所属的代码块内可见,而无法在代码块之外进行访问。在 C 语言中,由花括号包围的代码组成一个代码块。 - 函数作用域:指在函数中定义的标识符的作用范围。这些标识符只在该函数内部可见,超出该函数就无法访问。函数可以形成带花括号的块作用域,而参数列表中声明的标识符,作用范围为整个函数。
- 文件作用域:指在一个源文件中定义的标识符的作用范围。这种作用域的标识符可以在整个文件中访问。文件作用域中定义的变量被称为全局变量,因为它们可以在整个文件中访问。
在默认情况下,任何在代码块内声明的变量都属于自动存储类别的变量。自动变量在程序执行到其所在代码块时被创建,在离开该代码块时被销毁。这段时间被称为变量的生命周期。
作用域和生命周期的区别:
- 作用域是指标识符和数据对象之间的关联关系存在的区域
- 生命周期是指数据对象从创建到销毁的持续时间,即数据对象存在的周期。
函数原型
前面说过,函数必须先声明,后使用。由于程序总是先运行main()函数,导致所有其他函数都必须在main()函数之前声明。但是,main()是整个程序的入口,也是主要逻辑,放在最前面比较好。另一方面,对于函数较多的程序,保证每个函数的顺序正确,会变得很麻烦。C 语言提供的解决方法是,只要在程序开头处给出函数原型,函数就可以先使用、后声明。
所谓函数原型,就是提前告诉编译器,每个函数的返回类型和参数类型。其他信息都不需要,也不用包括函数体,具体的函数实现可以后面再补上。
函数原型包括参数名也可以,虽然这样对于编译器是多余的,但是阅读代码的时候,有助于理解函数的意图。
1
2
3
4
5
6
7
8
9
int twice(int); // 函数原型
int main(int num) {
return twice(num);
}
int twice(int num) {
return 2 * num;
}
注意,函数原型必须以分号结尾。
一般来说,每个源码文件的头部,都会给出当前脚本使用的所有函数的原型。
函数说明符
extern 说明符
对于多文件的项目,源码文件会用到其他文件声明的函数。这时,当前文件里面,需要给出外部函数的原型,并用 extern 说明该函数的定义来自其他文件。
1
2
3
4
5
6
7
extern int foo(int arg1, char arg2); // 声明该函数来自其他文件
int main(void) {
int a = foo(2, 3);
// ...
return 0;
}
不过,由于函数原型默认就是extern,所以上面不加extern,效果也是一样的。
static 说明符
默认情况下,每次调用函数时,函数的内部变量都会重新初始化,不会保留上一次运行的值。static说明符可以改变这种行为。
static用于函数内部声明变量时,表示该变量只需要初始化一次,不需要在每次调用时都进行初始化。也就是说,它的值在两次调用之间保持不变。
1
2
3
4
5
6
7
8
9
10
11
12
#include <stdio.h>
void counter(void) {
static int count = 1; // 只初始化一次
printf("%d\n", count);
count++;
}
int main(void) {
counter(); // 1
counter(); // 2
counter(); // 3
counter(); // 4
}
注意,static修饰的变量初始化时,只能赋值为常量,不能赋值为变量。
1
2
int i = 3;
static int j = i; // 错误
在块作用域中,static声明的变量有默认值 0
1
2
3
static int foo;
// 等同于
static int foo = 0;
static可以用来修饰函数本身,表示该函数只能在当前文件里使用。也可以用在参数里面,修饰参数数组。
1
2
3
int sum_array(int a[static 3], int n) {
// ...
}
static对程序行为不会有任何影响,只是用来告诉编译器,该数组长度至少为 3,某些情况下可以加快程序运行速度。另外,需要注意的是,对于多维数组的参数,static仅可用于第一维的说明。
const 说明符
函数参数里面的const说明符,表示函数内部不得修改该参数变量。例如,函数f()的参数是一个指针 p,函数内部可能会改掉它所指向的值*p,从而影响到函数外部。
1
2
3
void f(int* p) {
*p = 0;
}
为了避免这种情况,可以在声明函数时,在指针参数前面加上const说明符,告诉编译器,函数内部不能修改该参数所指向的值。
1
2
3
4
void f(const int* p) // const指定不能修改指针p指向的值
{
*p = 0; // 该行报错
}
但是上面这种写法,只限制修改 p 所指向的值,而 p 本身的地址是可以修改的。
1
2
3
4
void f(const int* p) {
int x = 13;
p = &x; // p本身是可以修改,const只限定*p不能修改。
}
如果想限制修改 p,可以把const放在 p 前面。
1
2
3
4
void f(int* const p) {
int x = 13;
p = &x; // 该行报错
}
如果想同时限制修改 p 和*p,需要使用两个const。
1
2
3
void f(const int* const p) {
// ...
}
exit()
头文件stdlib.h里面定义了一个exit()函数,用来终止整个程序的运行。一旦执行到该函数,程序就会立即结束。
exit()可以向程序外部返回一个值,它的参数就是程序的返回值。一般来说,使用两个常量作为它的参数:
EXIT_SUCCESS(相当于 0)表示程序运行成功EXIT_FAILURE(相当于 1)表示程序异常中止。
在main()函数里面,exit()等价于使用return语句。其他函数使用exit(),就是终止整个程序的运行,没有其他作用。
此外,头文件stdlib.h还提供了一个atexit()函数,用来登记exit()执行时额外执行的函数,用来做一些退出程序时的收尾工作。
atexit()的参数是一个函数指针。注意,它的参数函数(下例的print)不能接受参数,也不能有返回值。
1
2
3
4
5
6
void print(void) {
printf("something wrong!\n");
}
atexit(print);
exit(EXIT_FAILURE);
exit()执行时会先自动调用atexit()登记的print()函数,然后再终止程序。
可变参数
有些函数的参数数量是不确定的,声明函数的时候,可以使用省略号...表示可变数量的参数。...符号必须放在参数序列的结尾,否则会报错。
1
int printf(const char* format, ...);
头文件stdarg.h定义了一些宏,可以操作可变参数。
va_list:一个数据类型,用来定义一个可变参数对象。它必须在操作可变参数时,首先使用。va_start:一个函数,用来初始化可变参数对象。它接受两个参数,第一个参数是可变参数对象,第二个参数是原始函数里面,可变参数之前的那个参数,用来为可变参数定位。va_arg:一个函数,用来取出当前那个可变参数,每次调用后,内部指针就会指向下一个可变参数。它接受两个参数,第一个是可变参数对象,第二个是当前可变参数的类型。va_end:一个函数,用来清理可变参数对象。
1
2
3
4
5
6
7
8
9
10
double average(int i, ...) {
double total = 0;
va_list ap;
va_start(ap, i);
for (int j = 1; j <= i; ++j) {
total += va_arg(ap, double);
}
va_end(ap);
return total / i;
}
数据结构
Array
数组初始化
数组是一组相同类型的值,按照顺序储存在一起。声明数组时,必须给出数组的大小。
1
2
3
int a[10]; // a是一个长度为10的整型数组,第一个元素是a[0],最后一个元素是a[9]
a[0] = 100; // 通过数组下标对指定位置进行赋值。
注意,如果引用不存在的数组成员(即越界访问数组),并不会报错,所以必须非常小心。
1
2
int scores[100];
scores[100] = 51;
数组scores只有 100 个成员,因此scores[100]这个位置是不存在的。但是,引用这个位置并不会报错,会正常运行,使得紧跟在scores后面的那块内存区域被赋值,而那实际上是其他变量的区域,因此不知不觉就更改了其他变量的值。这很容易引发错误,而且难以发现。
数组也可以在声明时,使用大括号,同时对每一个成员赋值。
1
int a[5] = {22, 37, 3490, 18, 95};
注意,使用大括号赋值时,必须在数组声明时赋值,否则编译时会报错。
1
2
int a[5];
a = {22, 37, 3490, 18, 95}; // 报错
报错的原因是,C 语言规定,数组变量一旦声明,就不得修改数组变量指向的地址。由于同样的原因,数组赋值之后,再用大括号修改值,也是不允许的。
使用大括号赋值时,大括号里面的值不能多于数组的长度,否则编译时会报错。
如果大括号里面的值,少于数组的成员数量,那么未赋值的成员自动初始化为 0。
1
2
3
int a[5] = {22, 37, 3490};
// 等同于
int a[5] = {22, 37, 3490, 0, 0};
如果要将整个数组的每一个成员都设置为零,最简单的写法就是下面这样。
1
int a[100] = {0};
数组初始化时,可以指定为哪些位置的成员赋值。比如,下面的例子中,数组的 2 号、9 号、14 号位置被赋值,其他位置的值都自动设为 0。
1
int a[15] = {[2] = 29, [9] = 7, [14] = 48};
指定位置的赋值可以不按照顺序,下面的写法与上面的例子是等价的。
1
int a[15] = {[9] = 7, [14] = 48, [2] = 29};
指定位置的赋值与顺序赋值,可以结合使用。比如,下面的例子中,0 号、5 号、6 号、10 号、11 号被赋值。
1
int a[15] = {1, [5] = 10, 11, [10] = 20, 21}
C 语言允许省略方括号里面的数组成员数量,这时将根据大括号里面的值的数量,自动确定数组的长度。
1
2
3
int a[] = {22, 37, 3490};
// 等同于
int a[3] = {22, 37, 3490};
省略成员数量时,如果同时采用指定位置的赋值,那么数组长度将是最大的指定位置再加 1。
1
int a[] = {[2] = 6, [9] = 12}; // 最大指定位置是9,所以数组的长度是10。
数组长度
sizeof 运算符会返回整个数组的字节长度。由于数组成员都是同一个类型,每个成员的字节长度都是一样的,所以数组整体的字节长度除以某个数组成员的字节长度,就可以得到数组的成员数量。
1
2
3
4
5
int a[] = {22, 37, 3490};
printf("%zu\n", sizeof(a)); // 12
printf("%zu\n", sizeof(a[0])); // 4
printf("%zu\n", sizeof(x) / sizeof(a[0])); // 3
注意,sizeof返回值的数据类型是size_t,在printf()里面的占位符,要用%zd或%zu。
多维数组
C 语言允许声明多个维度的数组,有多少个维度,就用多少个方括号。
1
int board[10][10];
多维数组可以理解成,上层维度的每个成员本身就是一个数组。比如上例中,第一个维度的每个成员本身就是一个有 10 个成员的数组,因此整个二维数组共有 100 个成员(10 x 10 = 100)。
引用二维数组的每个成员时,需要使用两个方括号,同时指定两个维度。
1
2
board[0][0] = 13;
board[9][9] = 13;
注意,board[0][0]不能写成board[0, 0],因为0, 0是一个逗号表达式,返回第二个值,所以board[0, 0]等同于board[0]。
多维数组也可以使用大括号,一次性对所有成员赋值。
1
2
3
4
int a[2][5] = {
{0, 1, 2, 3, 4},
{5, 6, 7, 8, 9}
};
多维数组也可以指定位置,进行初始化赋值。如果有缺少的成员会自动设置为 0。如下所示,数组初始化时指定了[0][0]和[1][1]位置的值,其他位置就自动设为 0。
1
int a[2][2] = {[0][0] = 1, [1][1] = 2};
不管数组有多少维度,在内存里面都是线性存储,a[0][0]的后面是a[0][1],a[0][1]的后面是a[1][0],以此类推。因此,多维数组也可以使用单层大括号赋值,下面的语句与上面的赋值语句是完全等同的。
1
int a[2][2] = {1, 0, 0, 2};
变长数组
数组声明的时候,数组长度除了使用常量,也可以使用变量。这叫做变长数组(variable-length array,简称 VLA)。
1
2
int n = x + y;
int arr[n];
变长数组的根本特征,就是数组长度只有运行时才能确定。它的好处是程序员不必在开发时,随意为数组指定一个估计的长度,程序可以在运行时为数组分配精确的长度。
任何长度需要运行时才能确定的数组,都是变长数组。而且变长数组也可以用于多维数组。
1
2
3
int m = 4;
int n = 5;
int c[m][n];
数组的地址
数组是一连串连续储存的同类型值,只要获得起始地址(首个成员的内存地址),就能推算出其他成员的地址。
1
2
3
4
int a[5] = {11, 22, 33, 44, 55};
int* p;
p = &a[0]; // 等同于 p = a;
printf("%d\n", *p); // 返回 11
由于数组的起始地址是常用操作,&array[0]的写法有点麻烦,C 语言提供了便利写法,数组名等同于起始地址,也就是说,数组名就是指向第一个成员(array[0])的指针。
这样的话,如果把数组名传入一个函数,就等同于传入一个指针变量。在函数内部,就可以通过这个指针变量获得整个数组。如果函数接受数组作为参数,函数原型可以写成下面这样。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
// 写法一
int sum(int arr[], int len);
// 写法二
int sum(int* arr, int len);
int sum(int* arr, int len) {
int i;
int total = 0;
// 假定数组有 10 个成员
for (i = 0; i < len; i++) {
total += arr[i];
}
return total;
}
传入一个整数数组,与传入一个整数指针是同一回事,数组符号[]与指针符号*是可以互换的。
*和&运算符也可以用于多维数组。
1
2
3
int a[4][2];
//
*(a[0]); // 取出 a[0][0] 的值,等同于 **a
注意,数组名指向的地址是不能更改的。声明数组时,编译器自动为数组分配了内存地址,这个地址与数组名是绑定的,不可更改,下面的代码会报错。这也导致不能将一个数组名赋值给另外一个数组名。
1
2
3
4
5
6
7
int a[5] = {1, 2, 3, 4, 5};
a = NULL; // 报错
int b[5] = a; // 报错
int b[5];
b = a; // 报错
数组指针的加减法
数组名可以进行加法和减法运算,等同于在数组成员之间前后移动,即从一个成员的内存地址移动到另一个成员的内存地址。
1
2
3
4
int a[5] = {11, 22, 33, 44, 55};
for (int i = 0; i < 5; i++) {
printf("%d\n", *(a + i)); // a + i的每轮循环每次都会指向下一个成员的地址
}
由于数组名与指针是等价的,所以下面的等式总是成立。因此,数组成员有两种访问方式,一种是使用方括号a[b],另一种是使用指针*(a + b)。
1
2
a[b] == *(a + b);
a[10] == *(a + 10);
如果指针变量 p 指向数组的一个成员,那么 p++就相当于指向下一个成员,这种方法常用来遍历数组。
1
2
3
4
5
6
7
int a[] = {11, 22, 33, 44, 55, 999};
int* p = a;
while (*p != 999) {
printf("%d\n", *p);
p++;
}
注意,数组名指向的地址是不能变的,所以上例中,不能直接对a进行自增,即a++的写法是错的,必须将a的地址赋值给指针变量p,然后对p进行自增。
遍历数组一般都是通过数组长度的比较来实现,但也可以通过数组起始地址和结束地址的比较来实现。只要起始地址小于结束地址,就表示还没有到达数组尾部。
1
2
3
4
5
6
7
8
9
10
int sum(int* start, int* end) {
int total = 0;
while (start < end) {
total += *start;
start++;
}
return total;
}
int arr[5] = {20, 10, 5, 39, 4};
printf("%i\n", sum(arr, arr + 5)); // arr是数组的起始地址,arr + 5是结束地址。
反过来,通过数组的减法,可以知道两个地址之间有多少个数组成员。
1
2
3
4
5
int arr[5] = {20, 10, 5, 39, 88};
int* p = arr;
while (*p != 88)
p++;
printf("%i\n", p - arr); // 返回 4
对于多维数组,数组指针的加减法对于不同维度,含义是不一样的。
1
2
3
4
int arr[4][2];
arr + 1; // 指针指向 arr[1]
arr[0] + 1; // 指针指向 arr[0][1]
数组的复制
由于数组名是指针,所以复制数组不能简单地复制数组名。
1
2
3
int* a;
int b[3] = {1, 2, 3};
a = b;
上面的写法,结果不是将数组b复制给数组a,而是让a和b指向同一个数组。
复制数组最简单的方法是使用循环,将数组元素逐个进行复制。
1
2
for (i = 0; i < N; i++)
a[i] = b[i];
另一种方法是使用memcpy()函数(定义在头文件string.h),直接把数组所在的那一段内存,再复制一份。这种方法要比循环复制数组成员要快。
1
memcpy(a, b, sizeof(b));
数组作为函数的参数
数组作为函数的参数,一般会同时传入数组名和数组长度。如下所示,函数sum_array()的第一个参数是数组本身,也就是数组名,第二个参数是数组长度。
1
2
3
4
5
int sum_array(int a[], int n) {
// ...
}
int a[] = {3, 5, 7, 3};
int sum = sum_array(a, 4);
由于数组名就是一个指针,如果只传数组名,那么函数只知道数组开始的地址,不知道结束的地址,所以才需要把数组长度也一起传入。
如果函数的参数是多维数组,那么除了第一维的长度可以当作参数传入函数,其他维的长度需要写入函数的定义。
1
2
3
4
5
6
7
8
int sum_array(int a[][4], int n) {
// ...
}
int a[2][4] = {
{1, 2, 3, 4},
{8, 9, 10, 11}
};
int sum = sum_array(a, 2);
函数sum_array()的参数是一个二维数组。第一个参数是数组本身a[][4],这时可以不写第一维的长度,因为它作为第二个参数,会传入函数,但是一定要写第二维的长度 4。
因为函数内部拿到的,只是数组的起始地址a,以及第一维的成员数量 2。如果要正确计算数组的结束地址,还必须知道第一维每个成员的字节长度。写成int a[][4],编译器就知道第一维每个成员本身也是一个数组,里面包含了 4 个整数,所以每个成员的字节长度就是4 * sizeof(int)。
变长数组作为函数参数时,写法略有不同。
1
2
3
4
5
int sum_array(int n, int a[n]) {
// ...
}
int a[] = {3, 5, 7, 3};
int sum = sum_array(4, a);
数组a[n]是一个变长数组,它的长度取决于变量n的值,只有运行时才能知道。所以,变量n作为参数时,顺序一定要在变长数组前面,这样运行时才能确定数组a[n]的长度,否则就会报错。
因为函数原型可以省略参数名,所以变长数组的原型中,可以使用*代替变量名,也可以省略变量名。
1
2
int sum_array(int, int [*]);
int sum_array(int, int []);
变长数组作为函数参数有一个好处,就是多维数组的参数声明,可以把后面的维度省掉。如下所示,函数sum_array()的参数是一个多维数组,按照原来的写法,一定要声明第二维的长度。但是使用变长数组的写法,就不用声明第二维长度了,因为它可以作为参数传入函数。
1
2
3
4
// 原来的写法
int sum_array(int a[][4], int n);
// 变长数组的写法
int sum_array(int n, int m, int a[n][m]);
C 语言还允许将数组字面量作为参数,传入函数。
1
2
3
4
5
6
// 数组变量作为参数
int a[] = {2, 3, 4, 5};
int sum = sum_array(a, 4);
// 数组字面量作为参数,省掉了数组变量的声明,直接将数组字面量传入函数
int sum = sum_array((int []){2, 3, 4, 5}, 4);
Struct
struct 声明
C 语言内置的数据类型,除了最基本的几种原始类型,只有数组属于复合类型,可以同时包含多个值,但是只能包含相同类型的数据,实际使用中并不够用。
为此,C 语言提供了 struct 关键字,允许自定义复合数据类型,将不同类型的值组合在一起。这样不仅为编程提供方便,也有利于增强代码的可读性。C 语言没有其他语言的对象(object)和类(class)的概念,struct 结构很大程度上提供了对象和类的功能。
1
2
3
4
5
6
struct person {
char name[20];
int gender;
double height;
double weight;
};
struct语句结尾的分号不能省略,否则很容易产生错误。
定义了新的数据类型以后,就可以声明该类型的变量,这与声明其他类型变量的写法是一样的。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
struct person mike; // 单独定义结构体变量
strcpy(mike.name, "mike"); // C中不能直接使用字符串进行赋值
mike.gender = 1; // 使用点运算符结合字段名来访问结构体的成员
mike.height = 185.00;
mike.weight = 65.00;
// 定义结构体变量的同时进行初始化
struct person *pTimmy = &timmy; // 定义结构体指针
// 由于点运算符.的优先级高于取值*,为了让取值*先运算,必须使用括号将*pTimmy括起来。
printf("%s\n", (*pTimmy).name);
// C语言提供了更加方便的写法,即成员间接运算符->,(*pTimmy).name等价于pTimmy->name
printf("%s\n", pTimmy->name);
除了逐一对属性赋值,也可以使用大括号,一次性对 struct 结构的所有属性赋值。
1
struct person timmy = {"timmy", 1, 170.00, 60.00};
如果大括号里面的值的数量,少于属性的数量,那么缺失的属性自动初始化为 0。另外,大括号里面的值的顺序必须与 struct 类型声明时属性的顺序一致。否则,必须为每个值指定属性名。
1
struct person jack = {.height=172.00, .name="jack"};
struct 的数据类型声明语句与变量的声明语句,可以合并为一个语句。
1
2
3
4
5
6
struct person {
char name[20];
int gender;
double height;
double weight;
} tylor;
如果类型标识符person只用在这一个地方,后面不再用到,这里可以将类型名省略。与其他变量声明语句一样,可以在声明变量的同时,对变量赋值。
1
2
3
4
5
6
7
struct {
char name[20];
int gender;
double height;
double weight;
} tom = {"tom", 1, 173.00, 60.00},
joe = {"joe", 0, 165.00, 50.00};
typedef命令可以为 struct 结构指定一个别名,这样使用起来更简洁。
1
2
3
4
5
6
7
typredef struct person {
char name[20];
int gender;
double height;
double weight;
};
person bob = {"bob", 0, 165.00, 50.00};
指针变量也可以指向 struct 结构。struct 结构也可以作为数组成员。
1
2
3
4
5
6
7
8
struct book {
char title[500];
char author[100];
float value;
}* b1;
struct book library[100];
library[0].value = 100;
struct 结构占用的存储空间,不是各个属性存储空间的总和,而是最大内存占用属性的存储空间的倍数,其他属性会添加空位与之对齐。这样可以加快读写速度,把内存占用划分成等长的区块,就可以快速在 Struct 结构体中定位到每个属性的起始地址。
1
2
3
4
5
6
struct foo {
int a; // 4个字节,再扩充4个字节
char* b; // 8个字节
char c; // 1个字节,再扩充7个字节
};
printf("%d\n", sizeof(struct foo)); // 返回:24
由于这个特性,在有必要的情况下,定义 Struct 结构体时,可以采用存储空间递减的顺序,定义每个属性,这样就能节省一些空间。例如,按照下面的排序方式,struct foo的内存占用就从 24 字节下降到 16 字节。
1
2
3
4
5
6
struct foo {
char c; // 1个字节
int a; // 4个字节,加上之前的字符类型共5个字节,因此再扩充3个字节即可
char* b; // 8个字节
};
printf("%d\n", sizeof(struct foo)); // 返回:16
struct 复制
struct 变量可以使用赋值运算符=,复制给另一个变量,这时会生成一个全新的副本。系统会分配一块新的内存空间,大小与原来的变量相同,把每个属性都复制过去,即原样生成了一份数据。
1
2
3
4
5
6
7
8
struct cat { char name[30]; short age; } a, b;
strcpy(a.name, "Hula");
a.age = 3;
b = a;
b.name[0] = 'M';
printf("%s\n", a.name); // Hula
printf("%s\n", b.name); // Mula
上面这个示例是有前提的,就是 struct 结构的属性必须定义成字符数组,才能复制数据。如果稍作修改,属性定义成字符指针,结果就不一样。
1
2
3
4
5
struct cat { char* name; short age; } a, b;
a.name = "Hula";
a.age = 3;
b = a;
name属性变成了一个字符指针,这时 a 赋值给 b,导致b.name也是同样的字符指针,指向同一个地址,也就是说两个属性共享同一个地址。因为这时,struct 结构内部保存的是一个指针,而不是上一个例子的数组,这时复制的就不是字符串本身,而是它的指针。并且,这个时候也没法修改字符串,因为字符指针指向的字符串是不能修改的。
另外,C 语言没有提供比较两个自定义数据结构是否相等的方法,无法用比较运算符,比如==和!=比较两个数据结构是否相等或不等。
struct 指针
如果将 struct 变量传入函数,函数内部得到的是一个原始值的副本。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
#include <stdio.h>
struct turtle {
char* name;
char* species;
int age;
};
void grow(struct turtle t) {
t.age = t.age + 1;
}
int main() {
struct turtle myTurtle = {"MyTurtle", "sea turtle", 99};
grow(myTurtle);
printf("Age is %i\n", myTurtle.age); // 输出 99
return 0;
}
执行完grow()以后,函数外部的 age 属性值根本没变。原因就是函数内部得到的是 struct 变量的副本,改变副本影响不到函数外部的原始数据。
通常情况下,用户希望传入函数的是同一份数据,函数内部修改数据以后,会反映在函数外部。而且,传入的是同一份数据,也有利于提高程序性能。这时就需要将 struct 变量的指针传入函数,通过指针来修改 struct 属性,就可以影响到函数外部。
1
2
3
4
void grow(struct turtle* t) {
(*t).age = (*t).age + 1;
}
grow(&myTurtle);
t 是 struct 结构的指针,调用函数时传入的是指针。struct 类型跟数组不一样,类型标识符本身并不是指针,所以传入时,指针必须写成&myTurtle。同时,函数内部也必须使用(*t).age的写法,从指针拿到 struct 结构本身。
上面示例中,(*t).age不能写成*t.age,因为点运算符.的优先级高于*。*t.age这种写法会将t.age看成一个指针,然后取它对应的值,会出现无法预料的结果。
(*t).age这样的写法很麻烦。C 语言就引入了一个新的箭头运算符->,可以从 struct 指针上直接获取属性,大大增强了代码的可读性。
1
2
3
4
void grow(struct turtle* t) {
t->age = t->age + 1;
}
grow(&myTurtle);
对于 struct 变量名,使用点运算符.获取属性;对于 struct 变量指针,使用箭头运算符->获取属性。以变量myStruct为例,假设 ptr 是它的指针,那么下面三种写法是同一回事。
1
2
struct turtle* ptr == &myTurtle;
myTurtle.age == (*ptr).age == ptr->age
struct 的嵌套
struct 结构的成员可以是另一个 struct 结构。
1
2
3
4
5
6
7
8
9
10
struct species {
char* name;
int kinds;
};
struct fish {
char* name;
int age;
struct species breed;
};
赋值的时候有以下 4 种写法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
// 写法一
struct fish shark = {"shark", 9, {"Selachimorpha", 500}};
// 写法二
struct species myBreed = {"Selachimorpha", 500};
struct fish shark = {"shark", 9, myBreed};
// 写法三
struct fish shark = {
.name="shark",
.age=9,
.breed={"Selachimorpha", 500}
};
// 写法四
struct fish shark = {
.name="shark",
.age=9,
.breed.name="Selachimorpha",
.breed.kinds=500
};
printf("Shark's species is %s", shark.breed.name);
引用breed属性的内部属性,要使用两次点运算符shark.breed.name。
struct 结构内部不仅可以引用其他结构,还可以自我引用,即结构内部引用当前结构。比如,链表结构的节点就可以写成下面这样。
1
2
3
4
struct node {
int data;
struct node* next; // node结构的next属性,就是指向另一个node实例的指针。
};
位字段
struct 还可以用来定义二进制位组成的数据结构,称为位字段(bit field),这对于操作底层的二进制数据非常有用。
1
2
3
4
5
6
7
8
struct {
unsigned int ab:1;
unsigned int cd:1;
unsigned int ef:1;
unsigned int gh:1;
} synth;
synth.ab = 0;
synth.cd = 1;
上面示例中,每个属性后面的:1表示指定这些属性只占用一个二进制位,所以这个数据结构一共是 4 个二进制位。注意,定义二进制位时,结构内部的各个属性只能是整数类型。
实际存储的时候,C 语言会按照int类型占用的字节数,存储一个位字段结构。如果有剩余的二进制位,可以使用未命名属性,填满那些位。也可以使用宽度为 0 的属性,表示占满当前字节剩余的二进制位,迫使下一个属性存储在下一个字节。
1
2
3
4
5
6
7
struct {
unsigned int field1 : 1;
unsigned int : 2; // 宽度为两个二进制位的未命名属性
unsigned int field2 : 1;
unsigned int : 0; // 占满当前字节剩余的二进制位
unsigned int field3 : 1;
} stuff;
弹性数组成员
很多时候,不能事先确定数组到底有多少个成员。如果声明数组的时候,事先给出一个很大的成员数,就会很浪费空间。C 语言提供了一个解决方法,叫做弹性数组成员(flexible array member)。
如果不能事先确定数组成员的数量时,可以定义一个 struct 结构。如下所示,struct vstring结构有两个属性。len属性用来记录数组chars的长度,chars属性是一个数组,但是没有给出成员数量。
1
2
3
4
struct vstring {
int len;
char chars[];
};
chars数组到底有多少个成员,可以在为vstring分配内存时确定。
1
2
struct vstring* str = malloc(sizeof(struct vstring) + n * sizeof(char));
str->len = n;
上面示例中,假定chars数组的成员数量是 n,只有在运行时才能知道 n 到底是多少。然后,就为struct vstring分配它需要的内存:它本身占用的内存长度,再加上 n 个数组成员占用的内存长度。最后,len属性记录一下 n 是多少。这样就可以让数组chars有 n 个成员,不用事先确定,可以跟运行时的需要保持一致。
弹性数组成员有一些专门的规则。首先,弹性成员的数组,必须是 struct 结构的最后一个属性。另外,除了弹性数组成员,struct 结构必须至少还有一个其他属性。
Union
在 C 语言中,Union 数据结构允许在相同的内存位置存储不同类型的数据,大小等于其最大成员的大小。使用 Union 时,同一时刻只能访问其中一个成员,因为其他成员的数据会被覆盖。这样做的最大好处是节省空间。
1
2
3
4
5
union quantity {
short count;
float weight;
float volume;
};
使用时,声明一个该类型的变量。下面展示了为 Union 结构赋值的三种写法。最后一种写法不指定属性名,就会赋值给第一个属性 count。
1
2
3
4
5
6
7
8
9
// 写法一
union quantity q;
q.count = 4;
// 写法二
union quantity q = {.count=4};
// 写法三
union quantity q = {4};
执行完上面的代码以后,q.count可以取到值,另外两个属性取不到值。
1
2
printf("count is %i\n", q.count); // count is 4
printf("weight is %f\n", q.weight); // 未定义行为
Union 结构也支持指针运算符->,且 Union 结构指针与它的属性有关,当前哪个属性能够取到值,它的指针就是对应的数据类型。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
union foo {
int a;
float b;
} x;
int* foo_int_p = (int *)&x;
float* foo_float_p = (float *)&x;
x.a = 12;
printf("%d\n", x.a); // 12
printf("%d\n", *foo_int_p); // 12
x.b = 3.141592;
printf("%f\n", x.b); // 3.141592
printf("%f\n", *foo_float_p); // 3.141592
Enum
如果一种数据类型的取值只有少数几种可能,并且每种取值都有自己的含义,为了提高代码的可读性,可以将它们定义为 Enum 类型(枚举类型)。
1
2
3
4
enum colors {RED, GREEN, BLUE};
printf("%d\n", RED); // 0
printf("%d\n", GREEN); // 1
printf("%d\n", BLUE); // 2
枚举可以让数据更简洁,更易读,通常用于表示一组相关的整数值,例如表示状态、错误代码等。枚举成员是常量,不能对它们赋值,只能将它们的值赋给其他的变量。
Enum 内部的常量名,遵守标识符的命名规范,但是通常都使用大写。
使用时,可以将变量声明为 Enum 类型。
1
2
3
4
enum colors color;
color = BLUE;
printf("%i\n", color); // 2
由于 Enum 的属性会自动声明为常量,所以有时候使用 Enum 的目的,不是为了自定义一种数据类型,而是为了声明一组常量。
由于 Enum 会自动编号,因此可以不必为常量赋值。C 语言会自动从 0 开始递增,为常量赋值。但是,C 语言也允许为 ENUM 常量指定值,不过只能指定为整数,不能是其他类型。因此,任何可以使用整数的场合,都可以使用 Enum 常量。
1
2
enum { ONE = 1, TWO, THREE };
printf("%d %d %d", ONE, TWO, THREE); // 1 2 3
Enum 常量可以是不连续的值,也可以是同一个值。
1
2
3
enum { X = 2, Y = 18, Z = -2 };
enum { X = 2, Y = 2, Z = 2 };
Enum 和预处理指令#define非常类似,#define在预处理阶段将名字替换成对应的值,枚举则是在编译阶段将名字替换成对应的值。
Enum 的作用域与变量相同。如果是在顶层声明,那么在整个文件内都有效;如果是在代码块内部声明,则只对该代码块有效。与使用 int 声明的常量相比,Enum 的好处是更清晰地表示代码意图。
字符串
双引号和单引号
C 语言没有单独的字符串类型,字符串被当作字符数组,即 char 类型的数组。编译器会给数组分配一段连续内存,所有字符储存在相邻的内存单元之中。字符数组有两种定义方式:
1
2
char hello[6] = {'H','e','l','l','o', '\0'}; // 单引号:通过单个字符定义字符型的数组
char hello[6] = "Hello"; // 双引号:通过字符串的方式来定义字符数组
C 语言规定当使用双引号定义字符串时,在字符串结尾会自动添加一个全是二进制 0 的字节,写作\0字符,表示字符串结束。
字符\0不同于字符0,前者的 ASCII 码是 0(二进制形式00000000),后者的 ASCII 码是 48(二进制形式00110000)。
所有字符串的最后一个字符,都是\0。这样做的好处是,C 语言不需要知道字符串的长度,就可以读取内存里面的字符串,只要发现有一个字符是\0,那么就知道字符串结束了。
注意,双引号里面是字符串,单引号里面是字符,两者不能互换。如果把 Hello 放在单引号里面,编译器会报错。
1
'Hello' // 报错
另一方面,即使双引号里面只有一个字符,比如"a",也依然被处理成字符串(存储为 2 个字节,包括一个借结束符),而不是字符'a'(存储为 1 个字节)。
如果字符串过长,可以在需要折行的地方,使用反斜杠\结尾,将一行拆成多行。
1
2
"hello \
world"
上面这种写法有一个缺点,就是第二行必须顶格书写,如果想包含缩进,那么缩进也会被计入字符串。为了解决这个问题,C 语言允许合并多个字符串字面量,只要这些字符串之间没有间隔,或者只有空格,C 语言会将它们自动合并。
1
2
3
4
5
6
7
char greeting[50] = "Hello, how are you today!";
// 等同于
char greeting[50] = "Hello, " "how are you " "today!";
// 等同于
char greeting[50] = "Hello, "
"how are you "
"today!";
字符串声明
字符串变量可以声明成一个字符数组,也可以声明成一个指针,指向字符数组。
1
2
3
4
// 写法一
char s[14] = "Hello, world!"; // 等同于 char s[] = "Hello, world!";
// 写法二
char* s = "Hello, world!";
如果采用第一种写法,由于字符数组的长度可以让编译器自动计算,所以声明时可以省略字符数组的长度。
字符数组的长度,可以大于字符串的实际长度,这样空出来的位置会被初始化为\0。
1
char s[50] = "hello"; // 后面空出来的44个位置,都会被初始化为\0
字符数组的长度,不能小于字符串的实际长度。否则会出现意料之外的错误,比如,如果结束字符不是\0,则printf在显示这个字符串时,就不知道显示到何处结束:
1
2
3
4
char hello[5] = "Hello";
printf("%s", hello);
Hello#@($0948#."
如果在定义数组大小时只指定其大小是 5,则这个数组中的元素分别是'H'、'e'、'l'、'l'、'o'。且在'o'之后并没有'\0',所以在printf显示这个字符串时,显示Hello之后,并不知道何时结束,所以就会继续显示,直到遇到一个'\0'为止,于是程序就出现了非预期的结果。
字符指针和字符数组,这两种声明字符串变量的写法基本是等价的,但是有两个差异。
第一个差异是:指针指向的字符串,在 C 语言内部被当作常量,不能修改字符串本身。使用数组声明字符串变量,就没有这个问题,可以修改数组的任意成员。
1
2
3
4
5
char* s = "Hello, world!";
s[0] = 'z'; // 错误
char s[] = "Hello, world!";
s[0] = 'z'; // 正常
- 声明为指针时,系统会将字符串的字面量保存在内存的常量区,这个区是不允许用户修改的。因此指针变量存储的值是一个指向常量区的内存地址,用户不能通过这个地址去修改常量区。
- 声明为数组时,编译器会给数组单独分配一段内存,字符串字面量会被编译器解释成字符数组,逐个字符写入这段新分配的内存之中,而这段新内存是允许修改的。
为了提醒用户,字符串声明为指针后不得修改,可以在声明时使用const说明符,保证该字符串是只读的。
1
const char* s = "Hello, world!";
第二个差异是:指针变量可以指向其它字符串。但是,字符数组变量不能指向另一个字符串。
1
2
3
4
5
6
7
8
9
10
11
char* s = "hello";
s = "world"; // 正常
char s[] = "hello";
s = "world"; // 报错,字符数组的数组名,总是指向初始化时的字符串地址,不能修改。
char s[10];
s = "abc"; // 报错
char s[10];
strcpy(s, "abc"); // 正常
数组变量所在的地址无法改变,或者说,编译器一旦为数组变量分配地址后,这个地址就绑定这个数组变量了,这种绑定关系是不变的。因此,C 语言中数组变量是一个不可修改的左值,即不能用赋值运算符为它重新赋值。
想要重新赋值,必须使用 C 语言原生提供的strcpy()函数,通过字符串拷贝完成赋值。这样做以后,数组变量的地址还是不变的,即strcpy()只是在原地址写入新的字符串,而不是让数组变量指向新的地址。
字符串操作
使用#include <string.h>导入字符串操作头文件。
strlen()
1
size_t strlen(const char* s);
strlen()函数返回字符串的字节长度,不包括末尾的空字符\0。它的参数是字符串变量,返回的是 size_t 类型的无符号整数,除非是极长的字符串,一般情况下当作 int 类型处理即可。
1
2
char* str = "hello";
int len = strlen(str); // 返回 5
注意,字符串长度strlen(str)与字符串变量长度sizeof(str),是两个不同的概念。strlen测量从第一个元素开始直到元素值为'\0'的字符串的长度,而sizeof测量数组本身占用的空间大小。
1
2
3
char s[50] = "hello";
printf("%d\n", strlen(s)); // 5
printf("%d\n", sizeof(s)); // 50
因此,字符串遍历的时候最好使用strlen,而不是sizeof。如果不使用这个strlen函数,可以通过判断字符串末尾的\0,手动计算字符串长度。
1
2
3
4
5
6
int my_strlen(char *s) {
int count = 0;
while (s[count] != '\0')
count++;
return count;
}
strcpy()
字符串的复制,不能使用赋值运算符,直接将一个字符串赋值给字符数组变量。因为数组的变量名是一个固定的地址,不能修改,使其指向另一个地址。
1
2
3
4
char str1[10];
char str2[10];
str1 = "abc"; // 报错
str2 = str1; // 报错
如果是字符指针,赋值运算符=只是将一个指针的地址复制给另一个指针,而不是复制字符串。如下所示,两个指针变量s1和s2指向同一字符串,而不是将字符串 s1 的内容复制给 s2。
1
2
3
4
char* s1;
char* s2;
s1 = "abc";
s2 = s1;
因此,C 语言提供了strcpy()函数,用于将一个字符串的内容复制到另一个字符串,相当于字符串赋值。
1
char* strcpy(char* dest, const char* source)
这个函数接受两个参数,第一个参数是目的字符串数组,第二个参数是源字符串数组。复制字符串之前,必须要保证第一个参数的长度不小于第二个参数,否则虽然不会报错,但会溢出第一个字符串变量的边界,发生难以预料的结果。第二个参数的 const 说明符,表示这个函数不会修改第二个字符串。
1
2
3
4
5
6
7
8
9
10
char s[] = "Hello, world!";
char t[100];
strcpy(t, s);
t[0] = 'z';
printf("%s\n", s); // 返回:"Hello, world!"
printf("%s\n", t); // 返回:"zello, world!"
strcpy(str, "Hello, world!"); // 也可以直接使用字符串常量进行赋值
strcpy()的返回值是一个字符串指针char*,指向第一个参数,即拷贝开始的位置。
1
2
3
4
5
6
7
char* s1 = "beast";
char s2[40] = "Be the best that you can be.";
char* ps;
ps = strcpy(s2 + 7, s1);
puts(s2); // 返回:Be the beast
puts(ps); // 返回:beast
puts(const char *str)函数用于把一个字符串写入到标准输出 stdout,直到\0字符,但不包括\0字符,同时换行符\n会被自动追加到输出中。
strcpy()返回值的另一个用途,是连续为多个字符数组赋值,比如下面调用两次strcpy(),完成两个字符串变量的赋值。
1
strcpy(str1, strcpy(str2, "abcd"));
另外,strcpy()的第一个参数最好是一个已经声明的数组,而不是声明后没有进行初始化的字符指针。
1
2
char* str;
strcpy(str, "hello world"); // 错误
上面代码的问题在于strcpy()将字符串分配给指针变量 str,但是 str 并没有进行初始化,指向的是一个随机的位置,因此字符串可能被复制到任意地方。
如果不用strcpy(),自己实现字符串的拷贝,可以用下面的代码。
1
2
3
4
5
6
7
8
9
10
11
char* strcpy(char* dest, const char* source) {
char* ptr = dest;
while (*dest++ = *source++); // 依次将source的每个字符赋值给dest,直到\0
return ptr;
}
int main(void) {
char str[25];
strcpy(str, "hello world");
printf("%s\n", str);
return 0;
}
strcpy()函数有安全风险,因为它并不检查目标字符串的长度,是否足够容纳源字符串的副本,可能导致写入溢出。如果不能保证不会发生溢出,建议使用下面的strncpy()函数代替。
strncpy()
1
2
3
4
5
char* strncpy(
char* dest,
char* src,
size_t n
);
strncpy()跟strcpy()的用法完全一样,只是多了第 3 个参数,用来指定复制的最大字符数,防止溢出目标字符串变量的边界。
如果达到最大字符数以后,源字符串仍然没有复制完,就会停止复制,这时目的字符串结尾将没有终止符\0,这一点务必注意。
1
2
strncpy(str1, str2, sizeof(str1) - 1); // 复制长度最多为str1的长度减去1
str1[sizeof(str1) - 1] = '\0'; // str1剩下的最后一位用于写入字符串的结尾标志\0
strncpy()也可以用来拷贝部分字符串。
1
2
3
4
5
6
char s1[40];
char s2[12] = "hello world";
strncpy(s1, s2, 5); // 只拷贝s2的前5个字符。
s1[5] = '\0';
puts(s1); // 返回:hello
strcat()
1
char* strcat(char* s1, const char* s2);
strcat()函数用于连接字符串。它接受两个字符串作为参数,把第二个字符串的副本添加到第一个字符串的末尾。这个函数会改变第一个字符串,但是第二个字符串不变。strcat()的返回值是一个字符串指针,指向第一个参数。
1
2
3
4
5
char s1[12] = "hello";
char s2[6] = "world";
strcat(s1, s2);
puts(s1); // 返回:helloworld
注意,strcat()的第一个参数的长度,必须足以容纳添加第二个参数字符串。否则,拼接后的字符串会溢出第一个字符串的边界,写入相邻的内存单元,这是很危险的,建议使用下面的strncat()代替。
strncat()
1
2
3
4
5
char* strncat(
const char* dest,
const char* src,
size_t n
);
strncat()用于连接两个字符串,用法与strcat()完全一致,只是增加了第三个参数,指定最大添加的字符数。在添加过程中,一旦达到指定的字符数,或者在源字符串中遇到空字符\0,就不再添加了。
为了保证连接后的字符串,不超过目标字符串的长度,通常会写成下面这样。
1
strncat(str1, str2, sizeof(str1) - strlen(str1) - 1);
strncat()总是会在拼接结果的结尾,自动添加空字符\0,所以第三个参数的最大值,应该是 str1 的变量长度减去 str1 的字符串长度,再减去 1。
strcmp(), strncmp()
1
int strcmp(const char* s1, const char* s2);
strcmp()函数用于比较两个字符串的内容。比较原理是首先将 s1 字符串的第一个字符的 ACSII 值减去 s2 第一个字符的 ACSII 值,然后自左向右逐个字符相比,直到出现不同的字符或遇\0为止。
因此,如果两个字符串相同,返回值为 0;如果 s1 小于 s2,返回值小于 0;如果 s1 大于 s2,返回值大于 0。
相比于strcmp()函数,strncmp()函数增加了第三个参数 n,指定了比较的字符数。
1
2
3
4
5
int strncmp(
const char* s1,
const char* s2,
size_t n
);
sprintf(),snprintf()
1
int sprintf(char* s, const char* format, ...);
sprintf()函数位于头文件<stdio.h>中,跟printf()类似,但是用于将数据写入字符串,而不是输出到显示器。
sprintf()的第一个参数是字符串指针变量,其余参数和printf()相同,即第二个参数是格式字符串,后面的参数是待写入的变量列表。返回值是写入变量的字符数量,不计入尾部的\0。如果遇到错误,返回负值。
1
2
3
4
5
6
char first[6] = "hello";
char last[6] = "world";
char s[40];
sprintf(s, "%s %s", first, last);
printf("%s\n", s); // 返回:hello world
sprintf()有严重的安全风险,如果写入的字符串过长,超过了目标字符串的长度,sprintf()依然会将其写入,导致发生溢出。为了控制写入的字符串的长度,C 语言又提供了另一个函数snprintf()。
snprintf()总是会自动写入字符串结尾的空字符。如果你尝试写入的字符数超过指定的最大字符数,该函数会写入 n - 1 个字符,留出最后一个位置写入空字符。
1
snprintf(s, 12, "%s %s", "hello", "world"); // 写入字符串的最大长度不超过12
snprintf()的返回值是写入格式字符串的字符数量(不计入尾部的\0)。如果 n 足够大,返回值应该小于 n,但是有时候格式字符串的长度可能大于 n,那么这时返回值会大于 n,但实际上真正写入变量的还是 n-1 个字符。如果遇到错误,返回一个负值。
因此,返回值只有在非负并且小于 n 时,才能确认完整的格式字符串写入了变量。
字符串数组
如果一个数组的每个成员都是一个字符串,需要通过二维的字符数组实现。每个字符串本身是一个字符数组,多个字符串再组成一个数组。
1
2
3
4
5
6
7
8
9
char weekdays[7][10] = {
"Monday",
"Tuesday",
"Wednesday",
"Thursday",
"Friday",
"Saturday",
"Sunday"
};
数组的第二维,长度统一定为 10,有点浪费空间,因为大多数成员的长度都小于 10。解决方法就是把数组的第二维,从字符数组改成字符指针。
1
2
3
4
5
6
7
8
9
char* weekdays[] = {
"Monday",
"Tuesday",
"Wednesday",
"Thursday",
"Friday",
"Saturday",
"Sunday"
};
上面的字符串数组,其实是一个一维数组,成员就是 7 个字符指针,每个指针指向一个字符串(字符数组)。
标准 IO 操作
C 语言提供了一些函数,用于与外部设备通信,称为输入输出函数,简称 I/O 函数。输入(import)指的是获取外部数据,输出(export)指的是向外部传递数据。
缓存和字节流
严格地说,输入输出函数并不是直接与外部设备通信,而是通过缓存(buffer)进行间接通信。
普通文件一般都保存在磁盘上面,跟 CPU 相比,磁盘读取或写入数据是一个很慢的操作。所以,程序直接读写磁盘是不可行的,可能每执行一行命令,都必须等半天。C 语言的解决方案,就是只要打开一个文件,就在内存里面为这个文件设置一个缓存区。
- 程序向文件写入数据时,程序先把数据放入缓存,等到缓存满了,再把里面的数据会一次性写入磁盘文件。这时,缓存区就空了,程序再把新的数据放入缓存,重复整个过程。
- 程序从文件读取数据时,文件先把一部分数据放到缓存里面,然后程序从缓存获取数据,等到缓存空了,磁盘文件再把新的数据放入缓存,重复整个过程。
内存的读写速度比磁盘快得多,缓存的设计减少了读写磁盘的次数,大大提高了程序的执行效率。另外,一次性移动大块数据,要比多次移动小块数据快得多。
这种读写模式,对于程序来说,就有点像水流(stream),不是一次性读取或写入所有数据,而是一个持续不断的过程。先操作一部分数据,等到缓存吞吐完这部分数据,再操作下一部分数据。这个过程就叫做字节流操作。
由于缓存读完就空了,所以字节流读取都是只能读一次,第二次就读不到了。这跟读取文件很不一样。
C 语言的输入输出函数,凡是涉及读写文件,都是属于字节流操作。
- 输入函数从文件获取数据,操作的是输入流;
- 输出函数向文件写入数据,操作的是输出流。
printf()
用于屏幕输出。定义在头文件stdio.h中。
函数名字里面的 f 代表 format(格式化),表示可以定制输出文本的格式。
printf()不会在行尾自动添加换行符,运行结束后,光标就停留在输出结束的地方,不会自动换行。为了让光标移到下一行的开头,可以在输出文本的结尾,添加一个换行符\n。
1
printf("Hello World\n");
占位符
printf()可以在输出文本中指定占位符。占位符指的是这个位置可以用其他值代入。如下所示,占位符的第一个字符一律为百分号%,第二个字符表示占位符的类型,%i表示这里代入的值必须是一个整数。
1
printf("There are %i apples\n", 3); // 输出 There are 3 apples
输出文本里面可以使用多个占位符。printf()参数与占位符是一一对应关系,如果有 n 个占位符,printf()的参数就应该有 n + 1 个。如果参数个数少于对应的占位符,printf()可能会输出内存中的任意值。
占位符有许多种类,与 C 语言的数据类型相对应。下面按照字母顺序,列出printf()常用的占位符:
| %a, %A | 浮点数 |
|---|---|
| %c | 字符 |
| %d, %i | 十进制整数 |
| %e, %E, %Le | 科学计数法表示的浮点数(float 和 double 类型),Le 为 long double 类型 |
| %f, %Lf | 普通浮点数(float 和 double 类型),Lf 为 long double 类型 |
| %g, %G | 6 个有效数字的浮点数。整数部分超过 6 位,就自动转为科学计数法 |
| %hd, %ho, %hx, %hu | 不同限定下的 short int 类型(十进制、八进制、十六进制、无符号) |
| %ld, %lo, %lx, %lu | 不同限定下的 long int 类型,限定类型同上 |
| %lld, %llo, %llx, %llu | 不同限定下的 long long int 类型,限定类型同上 |
| %n | 已输出的字符串数量。该占位符本身不输出,只将值存储在指定变量之中 |
| %o | 八进制整数 |
| %p | 指针 |
| %s | 字符串 |
| %u | 无符号整数 |
| %x | 十六进制整数 |
| %zd | size_t 类型 |
| %% | 输出一个百分号 |
输出格式
上面的表格列出了一些常见的输出格式,完整的输出格式语法由以下五个元素组成。
- 标志:零个或多个标志字符,如
-表示采用左对齐;+表示总是显示正负号;#与 o、x 或 X 说明符一起使用时,非零值前面会分别显示 0、0x 或 0X,与 e、E 和 f 一起使用时,会强制输出包含一个小数点;0表示用 0 来填充,而不是空格。 - 最小字段宽度:用十进制整数表示的最小字段宽度,确定转换结果的最小字符数,如果转换结果的字符数不足最小字段宽度,则会用空格或零来填充空白。
- 精度:用点号表示的精度范围,后面可以跟一个十进制整数,定义转换结果的小数点后位数或部分字符数。
- 长度指示符:用字母组合来表示,它们用于指定转换参数的数据类型或大小。
- 转换操作:用单个字符表示的转换操作,操作定义了将转换参数转换为输出字符的方式。
1
2
3
4
5
6
7
8
9
printf("%+d\n", 123); // 总是显示正负号,输出 +123
printf("%5d\n", 123); // 最小字段宽度为5,输出为 " 123"
printf("%-5d\n", 123); // 采用左对齐显示,输出为 "123 "
printf("Number is %.2f\n", 0.5); // 小数点后2位,输出 Number is 0.50
printf("%.5s\n", "hello world"); // 输出部分字符串,输出 hello
最小宽度和小数位数这两个限定值,都可以用*代替,通过printf()的参数传入。
1
2
3
printf("%*.*f\n", 6, 2, 0.5);
// 等同于
printf("%6.2f\n", 0.5);
scanf()
scanf()可以处理用户的输入,将其存入变量。它的第一个参数是一个格式字符串,里面会放置占位符,它的其余参数就是存放用户输入的变量,格式字符串里面有多少个占位符,就有多少个变量。
1
scanf("%d%f", &i, &j); // 用户输入一个整数和一个浮点数,依次放入变量i和j中
scanf()处理数值占位符时,会自动过滤空白字符,包括空格、制表符、换行符等。所以,用户输入的数据之间,有一个或多个空格不影响 scanf()解读数据。另外,用户使用回车键,将输入分成几行,也不影响解读。
scanf()处理用户输入的原理是,用户的输入先放入缓存,等到按下回车键后,按照占位符对缓存进行解读。解读用户输入时,会从上一次解读遗留的第一个字符开始,直到读完缓存,或遇到第一个不符合条件的字符为止。
1
2
3
4
5
6
7
int x;
float y;
scanf("%d", &x);
scanf("%f", &y);
// 用户输入 " -13.45e12# 0" 得到 x=-13 y=0.45e12
上面示例中,scanf()读取用户输入时,%d占位符会忽略起首的空格,从-处开始获取数据,读取到-13停下来,因为后面的.不属于整数的有效字符。这就是说,占位符%d会读到-13。
第二次调用scanf()时,就会从上一次停止解读的地方,继续往下读取。这一次读取的首字符是.,由于对应的占位符是%f,会读取到.45e12,这是采用科学计数法的浮点数格式。后面的#不属于浮点数的有效字符,所以会停在这里。
scanf()的返回值是一个整数,表示成功读取的变量个数。如果没有读取任何项,或者匹配失败,则返回 0。如果读取到文件结尾,则返回常量EOF,通常是-1。
占位符
scanf()常用的占位符如下,与printf()的占位符基本一致。
| %c | 字符 |
|---|---|
| %d | 十进制整数 |
| %f, %lf, %Lf | float、double、long double 类型的浮点数 |
| %s | 字符串 |
| %[] | 在方括号中指定一组匹配的字符%[0-9],遇到不在集合之中的字符,匹配将会停止 |
上面所有占位符之中,除了%c以外,都会自动忽略起首的空白字符。
占位符%c不忽略空白字符,总是返回当前第一个字符,无论该字符是否为空格。如果要强制跳过字符前的空白字符,可以写成scanf(" %c", &ch),即%c前加上一个空格,表示跳过零个或多个空白字符。
占位符%s不能简单地等同于字符串。它的规则是,从当前第一个非空白字符开始读起,直到遇到空白字符(即空格、换行符、制表符等)为止。因为%s不会包含空白字符,所以无法用来读取多个单词,除非多个%s一起使用。这也意味着,scanf()不适合读取可能包含空格的字符串。另外,scanf()遇到%s占位符,会在字符串变量末尾存储一个空字符\0。
此外,scanf()将字符串读入字符数组时,不会检测字符串是否超过了数组长度。所以,储存字符串时,很可能会超过数组的边界,导致预想不到的结果。为了防止这种情况,使用%s占位符时,应该指定读入字符串的最长长度,即写成%[m]s,其中的[m]是一个整数,表示读取字符串的最大长度,后面的字符将被丢弃。
1
2
char name[11];
scanf("%10s", name); // 最多读取用户输入的10个字符
赋值忽略符
有时,用户的输入可能不符合预定的格式。
1
scanf("%d-%d-%d", &year, &month, &day);
上面示例中,如果用户输入2020-01-01,就会正确解读出年、月、日。问题是用户可能输入其他格式,比如2020/01/01,这种情况下,scanf()解析数据就会失败。
为了避免这种情况,scanf()提供了一个赋值忽略符(assignment suppression character)*,类似于正则表达式中的万能匹配符。只要把*加在任何占位符的百分号后面,该占位符就不会返回值,解析后将被丢弃。
1
scanf("%d%*c%d%*c%d", &year, &month, &day);
%*c在%后面加入了赋值忽略符*,表示这个占位符没有对应的变量,解读后不必返回。
sscanf()
1
int sscanf(const char* s, const char* format, ...);
sscanf()函数与scanf()很类似,不同之处是sscanf()从字符串里面,而不是从用户输入获取数据。主要用来处理其他输入函数读入的字符串,从其中提取数据。
sscanf()的第一个参数是一个字符串指针,用来从其中获取数据。其他参数都与scanf()相同。
1
2
3
fgets(str, sizeof(str), stdin); // 从标准输入stdin获取了一行数据,存入字符数组str
sscanf(str, "%d%d", &i, &j); // 从字符串str里面提取两个整数,放入变量i和j
sscanf()的一个好处是,它的数据来源不是流数据,所以可以反复使用,不像scanf()的数据来源是流数据,只能读取一次。
getchar(),putchar()
getchar()函数返回用户从键盘输入的一个字符,使用时不带有任何参数。程序运行到这个命令就会暂停,等待用户从键盘输入,等同于使用scanf()方法读取一个字符。
1
2
3
4
5
char ch;
ch = getchar();
// 等同于
scanf("%c", &ch);
putchar()函数将它的参数字符输出到屏幕,等同于使用printf()输出一个字符。
1
2
3
putchar(ch);
// 等同于
printf("%c", ch);
由于getchar()返回读取的字符,所以可以用在循环条件之中。如下所示,只有读到的字符等于换行符\n,才会退出循环,常用来跳过某行。while循环的循环体没有任何语句,表示对该行不执行任何操作。
1
2
while (getchar() != '\n')
;
下面的例子是计算某一行的字符长度。
1
2
3
int len = 0;
while(getchar() != '\n')
len++;
下面的例子是跳过空格字符,循环结束后,变量ch等于第一个非空格字符。
1
2
while ((ch = getchar()) == ' ')
;
由于getchar()和putchar()这两个函数的用法,要比 scanf()和 printf()更简单、更快。如果操作单个字符,建议优先使用这两个函数。
puts()
puts()函数用于将参数字符串显示在屏幕stdout上,并且自动在字符串末尾添加换行符。
1
puts("Hello World");
文件 IO 操作
文件指针
C 语言提供了一个 FILE 数据结构,记录了操作一个文件所需要的信息。该结构定义在头文件stdio.h,所有文件操作函数都要通过这个数据结构,获取文件信息。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
#include <stdio.h>
int main(void) {
FILE* fp; // 定义一个文件指针fp
char c;
fp = fopen("hello.txt", "r");
if (fp == NULL) {
return -1;
}
c = fgetc(fp);
printf("%c\n", c);
fclose(fp);
return 0;
}
开始操作一个文件之前,就要定义一个指向该文件的 FILE 指针,相当于获取一块内存区域,用来保存文件信息。新建文件指针以后,一般会通过三个步骤进行文件操作:
- 使用
fopen()打开指定文件,返回一个 File 指针。如果出错,返回 NULL。- 它相当于将指定文件的信息与新建的文件指针相关联,在 FILE 结构内部记录了这样一些信息:文件内部的当前读写位置、读写报错的记录、文件结尾指示器、缓冲区开始位置的指针、文件标识符、一个计数器(统计拷贝进缓冲区的字节数)等等。后继的操作就可以使用这个指针(而不是文件名)来处理指定文件。同时,它还为文件建立一个缓存区。由于存在缓存区,也可以说
fopen()函数打开一个了流,后继的读写文件都是流模式。
- 它相当于将指定文件的信息与新建的文件指针相关联,在 FILE 结构内部记录了这样一些信息:文件内部的当前读写位置、读写报错的记录、文件结尾指示器、缓冲区开始位置的指针、文件标识符、一个计数器(统计拷贝进缓冲区的字节数)等等。后继的操作就可以使用这个指针(而不是文件名)来处理指定文件。同时,它还为文件建立一个缓存区。由于存在缓存区,也可以说
- 使用读写函数,从文件读取数据,或者向文件写入数据。
- 上面例子中使用了
fgetc()函数,从已经打开的文件里面,读取一个字符。fgetc()一调用,文件的数据块先拷贝到缓冲区。不同的计算机有不同的缓冲区大小,一般是 512 字节或是它的倍数,如 4096 或 16384。随着计算机硬盘容量越来越大,缓冲区也越来越大。 fgetc()从缓冲区读取数据,同时将文件指针内部的读写位置指示器,指向所读取字符的下一个字符。所有的文件读取函数都使用相同的缓冲区,后面再调用任何一个读取函数,都将从指示器指向的位置,即上一次读取函数停止的位置开始读取。- 当读取函数发现已读完缓冲区里面的所有字符时,会请求把下一个缓冲区大小的数据块,从文件拷贝到缓冲区中。读取函数就以这种方式,读完文件的所有内容,直到文件结尾。不过,上例是只从缓存区读取一个字符。当函数在缓冲区里面,读完文件的最后一个字符时,就把 FILE 结构里面的文件结尾指示器设置为真。于是,下一次再调用读取函数时,会返回常量 EOF。EOF 是一个整数值,代表文件结尾,一般是-1。
- 上面例子中使用了
fclose()关闭文件,同时清空缓存区。
fopen()
1
FILE* fopen(char* filename, char* mode);
fopen()函数用来打开文件。所有文件操作的第一步,都是使用fopen()打开指定文件。它接受两个参数。第一个参数是文件名(可以包含路径),第二个参数是模式字符串,指定对文件执行的操作,比如下面的例子中,r表示以读取模式打开文件。
1
fp = fopen("in.dat", "r");
成功打开文件以后,fopen()返回一个 FILE 指针,其他函数可以用这个指针操作文件。如果无法打开文件(比如文件不存在或没有权限),会返回空指针 NULL。所以,执行fopen()后,最好判断一下有没有打开成功。
1
2
3
4
5
fp = fopen("hello.txt", "r");
if (fp == NULL) {
printf("Can't open file!\n");
exit(EXIT_FAILURE);
}
fopen()的模式字符串有以下几种:
| r | 读模式,只用来读取数据。如果文件不存在,返回 NULL 指针 |
|---|---|
| w | 写模式,只用来写入数据。如果文件存在,文件长度会被截为 0,然后再写入;如果文件不存在,则创建该文件 |
| a | 写模式,只用来在文件尾部追加数据。如果文件不存在,则创建该文件 |
| r+ | 读写模式。如果文件存在,指针指向文件开始处,可以在文件头部添加数据。如果文件不存在,则打开文件失败,返回 NULL 指针 |
| w+ | 读写模式。如果文件存在,文件长度会被截为 0,然后再写入数据。这种模式实际上读不到数据,反而会擦掉数据。如果文件不存在,则创建该文件 |
| a+ | 读写模式。如果文件存在,指针指向文件结尾,可以在现有文件末尾添加内容。如果文件不存在,则创建该文件 |
fopen()函数会为打开的文件创建一个缓冲区。C 语言通过缓存区,以流的形式,向文件读写数据。
- 读模式下,创建的是读缓存区;
- 写模式下,创建的是写缓存区;
- 读写模式下,会同时创建两个缓冲区。
数据在文件里面,都是以二进制形式存储。但是,读取的时候,有不同的解读方法:
- 以原本的二进制形式解读,叫做二进制流;
- 将二进制数据转成文本,以文本形式解读,叫做文本流。
写入操作也是如此,分成以二进制写入和以文本写入,后者会多一个文本转二进制的步骤。
fopen()的模式字符串,默认是以文本流读写。如果添加b后缀(binary),就会以二进制流进行读写。比如,rb是读取二进制数据模式,wb是写入二进制数据模式。
模式字符串还有一个x后缀表示独占模式(exclusive)。如果文件已经存在,则打开文件失败;如果文件不存在,则新建文件,打开后不再允许其他程序或线程访问当前文件。比如,wx表示以独占模式写入文件,如果文件已经存在,就会打开失败。
标准流
Linux 系统默认提供三个已经打开的文件,它们的文件指针如下。
- stdin(标准输入):默认来源为键盘,文件指针编号为 0。
- stdout(标准输出):默认目的地为显示器,文件指针编号为 1。
- stderr(标准错误):默认目的地为显示器,文件指针编号为 2。
Linux 系统的文件,不一定是数据文件,也可以是设备文件,即文件代表一个可以读或写的设备。文件指针stdin默认是把键盘看作一个文件,读取这个文件,就能获取用户的键盘输入。同理,stdout和stderr默认是把显示器看作一个文件,将程序的运行结果写入这个文件,用户就能看到运行结果了。它们的区别是,stdout写入的是程序的正常运行结果,stderr写入的是程序的报错信息。
这三个输入和输出渠道,是 Linux 默认提供的,所以分别称为标准输入stdin、标准输出stdout和标准错误stderr。因为它们的实现是一样的,都是文件流,所以合称为标准流。
Linux 允许改变这三个文件指针(文件流)指向的文件,这称为重定向(redirection)。
如果标准输入不绑定键盘,而是绑定其他文件,可以在文件名前面加上小于号<跟在程序名后面。这叫做“输入重定向”(input redirection)。如下所示,demo程序代码里面的stdin,将指向文件in.dat,即从in.dat获取数据。
1
$ demo < in.dat
如果标准输出绑定其他文件,而不是显示器,可以在文件名前加上大于号>,跟在程序名后面。这叫做“输出重定向”(output redirection)。如下所示,demo程序代码里面的stdout,将指向文件out.dat,即向out.dat写入数据。
1
$ demo > out.dat
输出重定向>会先擦去out.dat的所有原有的内容,然后再写入。如果希望写入的信息追加在out.dat的结尾,可以使用>>符号。如下所示,demo程序代码里面的stdout,将从out.dat的文件结尾开始写入。
1
$ demo >> out.dat
标准错误的重定向符号是2>。其中的 2 代表文件指针的编号,即2>表示将 2 号文件指针的写入,重定向到err.txt。2 号文件指针就是标准错误stderr。如下所示,demo程序代码里面的stderr,会向文件err.txt写入报错信息。而stdout向文件out.dat写入。
1
$ demo > out.dat 2> err.txt
输入重定向和输出重定向,也可以结合在一条命令里面。
1
2
3
$ demo < in.dat > out.dat
// or
$ demo > out.dat < in.dat
重定向还有另一种情况,就是将一个程序的标准输出stdout,指向另一个程序的标准输入stdin,这时要使用 pipeline 符号|。如下所示,random程序代码里面写入到stdout的内容,会从sum程序代码里面的stdin中读取出来。
1
$ random | sum
fclose()
1
int fclose(FILE* stream);
fclose()用来关闭已经使用fopen()打开的文件。它接受一个文件指针 fp 作为参数。如果成功关闭文件,fclose()函数返回整数 0;如果操作失败(比如磁盘已满,或者出现 I/O 错误),则返回一个特殊值 EOF
1
2
if (fclose(fp) != 0)
printf("Something wrong.");
不再使用的文件,都应该使用fclose()关闭,否则无法释放资源。一般来说,系统对同时打开的文件数量有限制,及时关闭文件可以避免超过这个限制。
EOF
C 语言的文件操作函数的设计是,如果遇到文件结尾,就返回一个特殊值。程序接收到这个特殊值,就知道已经到达文件结尾了。
头文件stdio.h为这个特殊值定义了一个宏 EOF(End Of File 的缩写),它的值一般是-1。这是因为从文件读取的二进制值,不管作为无符号数字解释,还是作为 ASCII 码解释,都不可能是负值,所以可以很安全地返回-1,不会跟文件本身的数据相冲突。
需要注意的是,不像字符串结尾真的存储了\0这个值,EOF 并不存储在文件结尾,文件中并不存在这个值,完全是文件操作函数发现到达了文件结尾,而返回这个值。
freopen()
1
FILE* freopen(char* filename, char* mode, FILE stream);
freopen()用于新打开一个文件,直接关联到某个已经打开的文件指针。这样可以复用文件指针。
它跟fopen()相比,就是多出了第三个参数,表示要复用的文件指针。其他两个参数都一样,分别是文件名和打开模式。
1
2
freopen("output.txt", "w", stdout);
printf("hello");
上面示例将文件output.txt关联到stdout,此后向stdout写入的内容,都会写入output.txt。由于printf()默认就是输出到stdout,所以运行上面的代码以后,文件output.txt会被写入hello。
freopen()的返回值是它的第三个参数(文件指针)。如果打开失败(比如文件不存在),会返回空指针 NULL。
freopen()会自动关闭原先已经打开的文件,如果文件指针并没有指向已经打开的文件,则freopen()等同于fopen()。
1
2
3
4
int i, i2;
scanf("%d", &i);
freopen("someints.txt", "r", stdin);
scanf("%d", &i2);
上面例子中,一共调用了两次scanf(),第一次调用是从键盘读取,然后使用freopen()将stdin指针关联到某个文件,第二次调用就会从该文件读取。
某些系统允许使用freopen(),改变文件的打开模式。这时,freopen()的第一个参数应该是 NULL。
1
freopen(NULL, "wb", stdout); // 将stdout的打开模式从w改成了wb。
读取文件和判断状态函数
- fscanf 是一个用于从文件中读取格式化输入的库函数,与 scanf 函数类似,fscanf 函数根据格式字符串从文件中读取数据,并将读取的数据存储到指定的变量中。
- fgetc 是一个用于从文件中读取单个字符的库函数,fgetc 函数从一个 FILE 指针指向的文件中读取一个字符,并返回该字符的 ASCII 码,如果到达文件末尾或遇到读取错误,则返回 EOF(end of file)
- 使用 ferror 和 feof 两个函数来判断文件状态。
- ferror 用于检查文件是否发生错误。如果在对文件进行操作时发生错误,ferror 函数将返回一个非零值。
- feof 用于检查文件是否已经到达末尾。如果文件读取到达末尾,feof 函数将返回一个非零值。
- fgets 是一个用于从文件中读取一行字符串的库函数,fgets 函数从一个 FILE 指针指向的文件中读取一行字符串(包括换行符),并将读取的字符串存储到指定的字符数组中。当到达指定的最大字符数或遇到文件末尾时,读取操作会停止。
- fread 函数用于从文件中读取指定数量的数据并将其存储到给定的内存区域中。通常用于从二进制文件中读取数据(如整数、浮点数、结构体等)。
写入文件函数
- fputc 是一个用于向文件中写入单个字符的库函数,fputc 函数将一个字符(以整数形式表示的 ASCII 码)写入一个 FILE 指针指向的文件中。
- fputs 是一个用于向文件中写入字符串的库函数,fputs 函数将一个以空字符(’\0’)结尾的字符串写入一个 FILE 指针指向的文件中。
- fflush 是一个用于刷新文件缓冲区的库函数,当程序执行文件 I/O 操作时,操作系统通常会使用缓冲区来临时存储数据,以提高性能。当文件被关闭或程序结束时,缓存会被刷新,数据才真正被保存在文件中。fflush 函数可以强制将文件缓冲区中的数据写入文件中,以确保数据被立即保存。
- fwrite 函数用于将指定数量的数据从给定的内存区域写入文件中。通常用于将数据(如整数、浮点数、结构体等)以二进制形式写入文件中。
文件偏移函数
在 C 语言中,文件偏移(也称为文件指针或文件位置)表示当前在文件中的位置,用于读取和写入操作。当使用 fopen 函数打开一个文件时,文件偏移通常被设置为文件开头(对于读模式)或文件结尾(对于追加模式)。
实际上,文件结构中保存了一个表示当前文件读写位置的指针。在 fopen 函数打开文件后,这个指针指向文件中的第一个字节。当任意文件操作函数读写相应长度的字节后,指针也会偏移相应的长度。
例如:每次 fgetc 函数获取一个字节时,文件指针都会向后移动一个字节,每次 fgets 函数获取一行字符时,文件指针都会向后移动到下一行开始。
在 C 语言中操作文件偏移,可以使用以下几个函数:
- fseek 函数用于设置文件偏移至指定位置。
- ftell 函数用于获取当前文件偏移。
- rewind 函数用于将文件指针(文件偏移)重置回文件的开头位置。这个函数非常有用,特别是在处理文件时需要多次从头开始读取或操作的情况下。
位操作
位运算符是一组用于执行二进制数(通常表示为整数)的位级操作的运算符。这些运算符直接操作整数的二进制位,因此通常具有非常高的速度和效率。以下是 C 语言中的位运算符。
| &, | , ^, ~ | a&b | 位运算:与、或、异或、非 |
|---|---|---|---|
| », « | int n=10; n «2 | 位运算:左移 2 位后,n=40 |
取反运算符~
取反运算符~是一个一元运算符,用来将每一个二进制位变成相反值,即 0 变成 1,1 变成 0。~运算符不会改变变量的值,只是返回一个新的值。
1
~ 10010011 // 返回 01101100
与运算符&
与运算符&将两个值的每一个二进制位进行比较,返回一个新的值。当两个二进制位都为 1,就返回 1,否则返回 0。与运算符&可以与赋值运算符=结合,简写成&=。
1
2
3
4
5
6
7
10010011 & 00111101 // 返回 00010001
int val = 3;
val = val & 0377;
// 简写成
val &= 0377;
或运算符|
或运算符|将两个值的每一个二进制位进行比较,返回一个新的值。两个二进制位只要有一个为 1(包含两个都为 1 的情况),就返回 1,否则返回 0。或运算符|可以与赋值运算符=结合,简写成|=。
1
2
3
4
5
6
7
10010011 | 00111101 // 返回 10111111
int val = 3;
val = val | 0377;
// 简写为
val |= 0377;
异或运算符^
异或运算符^将两个值的每一个二进制位进行比较,返回一个新的值。两个二进制位有且仅有一个为 1,就返回 1,否则返回 0。(相异为 1,相同为 0),异或运算符^可以与赋值运算符=结合,简写成^=。
1
2
3
4
5
6
10010011 ^ 00111101 // 返回 10101110
int val = 3;
val = val ^ 0377;
// 简写为
val ^= 0377;
左移运算符«
左移运算符«将左侧运算数的每一位,向左移动指定的位数,尾部空出来的位置使用 0 填充。
1
10001010 << 2 // 返回 1000101000
10001010的每一个二进制位,都向左侧移动了两位。因此,左移运算符相当于将运算数乘以 2 的指定次方,比如左移 2 位相当于乘以 4。
左移运算符<<可以与赋值运算符=结合,简写成<<=。
1
2
3
4
int val = 1;
val = val << 2;
// 简写为
val <<= 2;
右移运算符»
右移运算符»将左侧运算数的每一位,向右移动指定的位数,尾部无法容纳的值将丢弃,头部空出来的位置使用 0 填充。
1
10001010 >> 2 // 返回 00100010
10001010的每一个二进制位,都向右移动两位。最低的两位 10 被丢弃,头部多出来的两位补 0,所以最后得到00100010。因此,右移运算符相当于将运算数除以 2 的指定次方,比如右移 2 位就相当于除以 4。
注意,右移运算符最好只用于无符号整数,不要用于负数。因为不同系统对于右移后如何处理负数的符号位,有不同的做法,可能会得到不一样的结果。
右移运算符>>可以与赋值运算符=结合,简写成>>=。
1
2
3
4
int val = 1;
val = val >> 2;
// 简写为
val >>= 2;
内存管理
内存四区
一般来说,由 C 编译的程序会在运行的时候在内存中占用一些空间,它们分为以下 4 个部分,称为内存四区:
静态区域:
- 代码区:包括只读存储区和文本区,其中只读存储区(常量区)存放数字、字符串等常量,文本区存放程序的机器代码(二进制代码)。
- 数据区:又称为静态存储区,用于存放静态变量和全局变量,这块内存在程序编译的时候就已经分配好,并存在于程序的整个运行期间。如果在汇编角度细分的话还可以分为更小的区:
- 初始化段(DATA 段) :存储程序中已初始化的全局变量和静态变量。
- 未初始化段(BSS 段) :存储未初始化的全局变量和静态变量。BSS 段在 DATA 段相邻的另一块区域,特点是在程序执行前 BBS 段自动清零,所以未初始化的全局变量和静态变量在程序执行前已经成为 0。
动态区域:
- 栈区(stack):用于存放函数参数、返回值和函数内部的变量(局部变量),由编译器分配和释放内存,从高地址向低地址增长。在创建进程时会有一个最大栈大小,操作方式类似于数据结构的栈。
- 堆区(heap):用于存放程序运行的整个过程中都存在的变量(全局变量),由用户手动分配和释放内存,当进程未调用 malloc 时是没有堆区的,只有调用 malloc 时分才会配一个堆区,并且在程序运行过程中可以动态增加堆区大小,从低地址向高地址增长。和数据结构的堆完全不同,操作方式类似于数据结构的链表。
相比于静态存储区,堆区的内存空间使用更加灵活,因为用户可以在不需要它的时候,随时将它释放掉,而静态存储区一直存在于程序的整个生命周期中。
堆区和栈区的详细对比
- 内存分配方式不同:
- 栈由编译器自动分配释放;
- 堆一般是由程序员分配释放,若程序员不释放的话,程序结束时可能由 OS 回收。
- 申请方式不同:
- 栈由系统自动分配,系统收回;
- 堆需要程序员自己申请,C 语言中用函数 malloc 分配空间,用 free 释放。
- 申请后系统的响应不同:
- 对于栈,只要栈的剩余空间大于所申请的空间,系统将为程序提供内存,否则将报异常提示栈溢出;
- 对于堆,首先应该知道操作系统有一个记录内存地址的链表,当系统收到程序的申请时,会遍历该链表,寻找第一个空间大于所申请的空间的堆结点,然后将该结点从空闲结点链表中删除,并将该结点的空间分配给程序。另外,大多数系统会在这块内存空间中的首地址处记录本次分配的大小,这样代码中的 delete 或 free 语句就能够正确的释放本次分配的内存空间。由于找到的堆结点的大小不一定正好等于申请的大小,系统会将多余的那部分重新放入空闲链表中。
- 申请的大小限制不同:
- 栈是向低地址扩展的数据结构,是一块连续的内存区域,栈顶的地址和栈的最大容量是系统预先规定好的,能从栈获得的空间较小。Windows 下一般大小是 1M 或 2M
- 堆是向高地址扩展的数据结构,是不连续的内存区域,这是由于系统是由链表来存储空闲内存地址,自然堆就是不连续的内存区域,且链表的遍历也是从低地址向高地址遍历的,堆得大小受限于计算机系统的有效虚拟内存空间,因此,堆获得的空间比较灵活,也比较大。
- 申请的效率不同:
- 栈由系统自动分配,速度快,但是程序员无法控制。
- 堆是由程序员自己分配,速度较慢,容易产生碎片,不过用起来方便。
- 堆和栈的存储内容不同:
- 在函数调用时,第一个进栈的是主函数中函数调用后的下一条指令的地址,然后是函数的各个参数,在大多数的 C 编译器中,参数是从右往左入栈的,当本次函数调用结束后,局部变量先出栈,然后是参数,最后栈顶指针指向最开始存的地址,也就是主函数中的下一条指令。
- 一般是在堆的头部用一个字节存放堆的大小,具体内容由程序员安排。
void 指针
每一块内存都有地址,通过指针变量可以获取指定地址的内存块。指针变量必须有类型,否则编译器不知道如何解读内存块保存的二进制数据。但是,向系统请求内存的时候,有时不确定会有什么样的数据写入内存,需要先获得内存块,稍后再确定写入的数据类型。
为了满足这种需求,C 语言提供了一种不定类型的指针,叫做 void 指针。它只有内存块的地址信息,没有类型信息,等到使用该块内存的时候,再向编译器补充说明,里面的数据类型是什么。
另一方面,void 指针等同于无类型指针,可以指向任意类型的数据,但是不能解读数据。void 指针与其他所有类型指针之间是互相转换关系,任一类型的指针都可以转为 void 指针,而 void 指针也可以转为任一类型的指针。
1
2
3
int x = 10;
void* p = &x; // 整数指针转为 void 指针
int* q = p; // void 指针转为整数指针
注意,由于不知道 void 指针指向什么类型的值,所以不能用*运算符取出它指向的值。
1
2
3
char a = 'X';
void* p = &a;
printf("%c\n", *p); // 报错
void 指针的重要之处在于,很多内存相关函数的返回值就是 void 指针,即只给出内存块的地址信息。
malloc()
动态内存管理使用的函数,都需要导入头文件<stdlib.h>才能进行使用。
1
void* malloc(size_t size)
malloc()函数向系统要求一段内存,系统就在堆区里面分配一段连续的内存块给它。它接受一个非负整数作为参数,表示所要分配的内存字节数,返回一个 void 指针,指向分配好的内存块。因为malloc()函数不知道将要存储在该块内存的数据是什么类型,只能返回一个无类型的 void 指针。
可以使用malloc()为任意类型的数据分配内存,常见的做法是先使用sizeof()函数,算出某种数据类型所需的字节长度,然后再将这个长度传给malloc()。
1
2
3
int* pInt = malloc(sizeof(int));
*pInt = 12;
printf("%d\n", *p); // 返回:12
有时候为了增加代码的可读性,可以对 malloc()返回的指针进行一次强制类型转换。
1
int* p = (int*) malloc(sizeof(int));
若 malloc 函数申请内存空间失败,它将返回 NULL。为 NULL 指针取值将导致程序崩溃。作为一个稳健的程序,建议每次通过 malloc 函数申请内存空间时都对返回值进行判断。
1
2
3
4
5
6
int *pInt = NULL;
pInt = malloc(sizeof(int));
if (pInt != NULL) {
*pInt = 12;
printf("%d", *pInt);
}
malloc()最常用的场合,就是为数组和自定义数据结构分配内存。
1
2
3
int* pInt = (int*) malloc(sizeof(int) * 10);
for (int i = 0; i < 10; i++)
pInt[i] = i * 5;
用malloc()来创建数组有一个好处,就是创建动态数组,即根据成员数量的不同,而创建长度不同的数组。
1
int* p = (int*) malloc(n * sizeof(int));
注意,malloc()不会对所分配的内存进行初始化,里面还保存着原来的值。如果没有初始化,就使用这段内存,可能从里面读到以前的值。程序员要自己负责初始化,比如,字符串初始化可以使用strcpy()函数。
1
2
char* p = malloc(4);
strcpy(p, "abc");
由于malloc()处理的是栈区内存,因此不能在函数体之外使用,否则会报错。
变长数组和动态数组的区别:
- 变长数组一般是在栈上分配,动态数组一般是在堆上分配。
- 变长数组在函数返回之后生命周期就结束了,而动态数组需要手动 free 释放才会销毁。
- 虽然变长数组可以运行期指定大小,但是大小一旦指定就不可变。而动态数组可以随需求扩容。
- 变长数组使用多了容易栈溢出,而且它在 c11 里只是可选特性,和标准 C++ 也不兼容,所以不建议过多使用。
- 动态数组的缺点在于堆分配比较耗时,频繁申请释放还可能会产生内存碎片。
总结:如果数组变量有局部性、知道其大小、且存储区域无须变动时,使用静态分配,否则使用动态分配
free()
1
void free(void* block)
free()用于释放malloc()函数分配的内存,将这块内存还给系统以便重新使用,否则这个内存块会一直占用到程序运行结束。
输入参数指向要释放的内存块的指针。这个指针应该是之前由malloc()函数返回的指针。如果传递给free()函数的指针不是这个函数返回的指针,或者已经被释放过,将导致未定义行为。
分配的内存块一旦释放,就不应该再次操作已经释放的地址,也不应该再次使用free()对该地址释放第二次。
1
2
3
4
5
6
7
int *pInt = NULL;
pInt = malloc(sizeof(int));
if (pInt != NULL) {
*pInt = 123;
printf("%d", *pInt);
free(pInt);
}
一个很常见的错误是,在函数内部分配了内存,但是函数调用结束时,没有使用free()释放内存。
1
2
3
4
5
6
7
8
9
10
11
#include <stdio.h>
#include <stdlib.h>
int main() {
while (1)
{
void* p = malloc(1024 * 1024);
printf("%d\n", p);
}
return 0;
}
函数gobble()内部分配了内存,但是没有写free(temp)。这会造成函数运行结束后,占用的内存块依然保留,如果多次调用gobble(),就会留下多个内存块。并且,由于指针 temp 已经消失了,程序将无法再通过任何方式使用或释放这些内存块,因此被称为内存泄漏(memory leak)。
具有内存泄漏问题的代码若长时间运行,会导致程序所占用的内存空间逐渐增大,直至没有可分配的内存空间,并无法再成功申请内存空间。
calloc()
1
void* calloc(size_t n, size_t size);
calloc()函数的作用与malloc()相似,也是分配内存块。两者的区别主要有两点:
calloc()接受两个参数,第一个参数是某种数据类型的值的数量,第二个是该数据类型的单位字节长度。calloc()会将所分配的内存全部初始化为 0。malloc()不会对内存进行初始化,如果想要初始化为 0,还要额外调用memset()函数。
1
2
3
4
5
int* p = calloc(10, sizeof(int));
// 等同于
int* p = malloc(sizeof(int) * 10);
memset(p, 0, sizeof(int) * 10);
realloc()
1
void* realloc(void* block, size_t size)
realloc()函数用于修改已经分配的内存块的大小,可以放大也可以缩小,返回一个指向新的内存块的指针。如果分配不成功,返回 NULL。它接受两个参数:
- block:已经分配好的内存块指针,由
malloc()或calloc()或realloc()产生。 - size:该内存块的新大小,单位为字节。
realloc()可能返回一个全新的地址(数据也会自动复制过去),也可能返回跟原来一样的地址。它会优先在原有内存块上进行缩减,尽量不移动数据,所以通常是返回原先的地址。如果新内存块小于原来的大小,则丢弃超出的部分;如果大于原来的大小,则不对新增的部分进行初始化,程序员可以自动调用memset()。
1
2
3
int* b;
b = malloc(sizeof(int) * 10); // b为指向10个成员的整型数组
b = realloc(b, sizeof(int) * 2000); // 调整为2000个成员的数组
realloc()的第一个参数可以是 NULL,这时就相当于新建一个指针。
1
2
3
char* p = realloc(NULL, 3490);
// 等同于
char* p = malloc(3490);
如果realloc()的第二个参数是 0,就会释放掉内存块。
由于有分配失败的可能,所以调用 realloc()以后,最好检查一下它的返回值是否为 NULL。分配失败时,原有内存块中的数据不会发生改变。
1
2
3
4
5
float* new_p = realloc(p, sizeof(*p * 40));
if (new_p == NULL) {
printf("Error reallocing\n");
return 1;
}
restrict 说明符
restrict 关键字是 C99 标准引入的,用于声明指针变量时告诉编译器,该块内存区域只能通过当前的指针访问,其他指针不能读写该块内存。这种指针称为受限指针(restrict pointer)。
1
2
int* restrict p;
p = malloc(sizeof(int)); // malloc函数返回的内存只能通过p来访问,不存在其他访问方式。
memcpy()
1
2
3
4
5
void* memcpy(
void* restrict dest,
void* restrict source,
size_t n // 要拷贝的字节数,注意字节数不等于成员数
);
memcpy()用于将一块内存拷贝到另一块内存。参数dest和source都是 void 指针,表示这里不限制指针类型,各种类型的内存数据都可以拷贝,两者都有 restrict 关键字,表示这两个内存块不应该有互相重叠的区域。
因为memcpy()只是将一段内存的值,复制到另一段内存,所以不需要知道内存里面的数据是什么类型。
1
2
3
4
char s[] = "Goats!";
char t[100];
memcpy(t, s, sizeof(s)); // 拷贝7个字节,包括终止符
printf("%s\n", t); // 返回:"Goats!"
memcpy()可以取代strcpy()进行字符串拷贝,而且是更好的方法,不仅更安全,速度也更快,但是它不检查字符串尾部的\0字符,所以要拷贝的字节数需要加上 1 来包括尾部的\0字符。
1
2
3
4
5
6
7
8
9
10
char* s = "hello world";
size_t len = strlen(s) + 1;
char *c = malloc(len);
if (c) {
// strcpy() 的写法
strcpy(c, s);
// memcpy() 的写法
memcpy(c, s, len);
}
memmove()
1
2
3
4
5
void* memmove(
void* dest,
void* source,
size_t n
);
memmove()函数用于将一段内存数据复制到另一段内存。它跟memcpy()的主要区别是,它允许目标区域与源区域有重叠。如果发生重叠,源区域的内容会被更改;如果没有重叠,它与memcpy()行为相同。
memmove()函数常用于批量移动数组中的元素,比如,将 a 数组中从a[1]开始的 99 个成员,都向前移动一个位置。
1
2
3
4
int a[100];
// ...
memmove(&a[0], &a[1], 99 * sizeof(int));
从字符串 x 的 5 号位置开始的 10 个字节,就是"Sweet Home",memmove()将其前移到 0 号位置,所以 x 就变成了"Sweet Home Home"。
1
2
3
char x[] = "Home Sweet Home";
printf("%s\n", (char *) memmove(x, &x[5], 10)); // 输出 Sweet Home Home
memcmp()
1
2
3
4
5
int memcmp(
const void* s1,
const void* s2,
size_t n
);
memcmp()函数用来比较两个内存区域。它接受三个参数,前两个参数是用来比较的指针,第三个参数指定比较的字节数。它的返回值是一个整数。两块内存区域的每个字节以字符形式解读,按照 ASCII 码的顺序进行比较,如果两者相同,返回 0;如果 s1 大于 s2,返回大于 0 的整数;如果 s1 小于 s2,返回小于 0 的整数。
1
2
3
char* s1 = "abc";
char* s2 = "acd";
int r = memcmp(s1, s2, 3); // 小于 0
变量说明符
C 语言允许声明变量的时候,加上一些特定的说明符(specifier),为编译器提供变量行为的额外信息。它的主要作用是帮助编译器优化代码,有时会对程序行为产生影响。
const
const 说明符表示变量是只读的,不得被修改。
1
2
const double PI = 3.14159;
PI = 3; // 报错
对于数组,const 表示数组成员不能修改。
1
2
const int arr[] = {1, 2, 3, 4};
arr[0] = 5; // 报错
对于指针变量,const 有两种写法,含义是不一样的。
- 如果 const 在
*前面,表示指针指向的值不可修改。
1
2
3
4
5
6
7
8
// 写法1
int const * x
// 写法2
const int * x
int p = 1
const int* x = &p;
(*x)++; // 报错
- 如果 const 在
*后面,表示指针包含的地址不可修改。
1
2
3
4
5
int* const x
int p = 1
int* const x = &p;
x++; // 报错
- 这两者可以结合起来,表示指针指向的值和包含的地址都不可修改。
1
const char* const x;
const 的一个用途,就是防止函数体内修改函数参数。如果某个参数在函数体内不会被修改,可以在函数声明时,对该参数添加 const 说明符。如下所示,函数find的参数数组arr有 const 说明符,就说明该数组在函数内部将保持不变。
1
void find(const int* arr, int n);
有一种情况需要注意,如果一个指针变量指向 const 变量,那么该指针变量也不应该被修改
1
2
3
const int i = 1;
int* j = &i;
*j = 2; // 报错
auto
auto 说明符表示该变量的存储,由编译器自主分配内存空间,且只存在于定义时所在的作用域,退出作用域时会自动释放。只要不是 extern 的变量(外部变量),都是由编译器自主分配内存空间的,这属于默认行为,所以该说明符没有实际作用,一般都省略不写。
1
2
3
auto int a;
// 等同于
int a;
static
static 说明符对于全局变量和局部变量有不同的含义:
- 静态全局变量:全局变量前加 static 修饰,该变量就成为了静态全局变量。普通全局变量对整个工程可见,其他文件可以使用 extern 外部声明后直接使用,而静态全局变量仅对当前文件可见,其他文件不可访问,其他文件可以定义与其同名的变量,两者互不影响。
- 静态局部变量:局部变量前加 static 修饰,该变量就成为了静态局部变量,类似于一个只用于函数内部的全局变量。普通局部变量在离开了被定义的函数后,就会被销毁,而静态局部变量的作用域一直到整个程序结束,并且即使在声明时未赋初值,编译器也会把它自动初始化为 0。
static 修饰的变量,初始化时,值不能等于变量,必须是常量。
1
2
int n = 10;
static m = n; // 报错
只在当前文件里面使用的函数也可以声明为 static,表明该函数只在当前文件使用,其他文件可以定义同名函数。
1
static int g(int i);
static 是一个很有用的关键字,使用得当可以使程序锦上添花。一个良好的编码风格通常会规定只用于本文件的函数和全局变量要全部使用 static 关键字声明。
extern
extern 说明符表示,该变量在其他文件里面声明,没有必要在当前文件里面为它分配空间。通常用来表示,该变量是多个文件共享的。
1
extern int a;
但是,变量声明时,同时进行初始化,extern 就会无效,这是为了防止多个 extern 对同一个变量进行多次初始化。
1
2
3
extern int i = 0; // extern 无效
// 等同于
int i = 0;
函数内部使用 extern 声明变量,就相当于该变量是静态存储,每次执行时都要从外部获取它的值。
函数本身默认是 extern,即该函数可以被外部文件共享,通常省略 extern 不写。如果只希望函数在当前文件可用,那就需要在函数前面加上 static。
1
2
3
extern int f(int i);
// 等同于
int f(int i);
extern 和#include 的区别
使用 include 可以将另一个文件全部包含进去,但是这样做的结果就是,被包含的文件中的所有的变量和方法都可以被这个文件使用,这样就变得不安全。如果只是希望一个文件使用另一个文件中的某个变量还是使用 extern 关键字更好。
此外一个项目里,一个.h 文件可能会被多个.c 文件包含,如果.h 文件中定义变量的话编译的时候就会报重复定义的错误。因此需要使用头文件守卫的方法,防止头文件被重复引用。
register
register 说明符向编译器表示,该变量是经常使用的,应该提供最快的读取速度,所以应该放进 CPU 寄存器。但是,编译器可以忽略这个说明符,不一定按照这个指示行事。
1
register int a;
register 只对声明在代码块内部的变量有效。
由于 register 变量不是保存在内存中,因此不能获取它的地址。如果数组设为 register,也不能获取整个数组或任一个数组成员的地址。
1
2
3
4
5
6
register int a;
int *p = &a; // 编译器报错
register int a[] = {11, 22, 33, 44, 55};
int p = a; // 报错
int a = *(a + 2); // 报错
历史上,CPU 内部的缓存,称为寄存器(register)。与内存相比,寄存器的访问速度快得多,所以使用它们可以提高速度。但是它们不在内存之中,所以没有内存地址,这就是为什么不能获取指向它们的指针地址。现代编译器已经有巨大的进步,会尽可能优化代码,按照自己的规则决定怎么利用好寄存器,取得最佳的执行速度,所以可能会忽视代码里面的 register 说明符,不保证一定会把这些变量放到寄存器。
volatile
volatile 说明符表示所声明的变量,可能会预想不到地发生变化(即其他程序可能会更改它的值),不受当前程序控制,因此编译器不要对这类变量进行优化,每次使用时都应该查询一下它的值。硬件设备的编程中,这个说明符很常用。
1
2
volatile int foo;
volatile int* bar;
volatile 的目的是阻止编译器对变量行为进行优化。
1
2
3
int foo = x;
// 其他语句,假设没有改变 x 的值
int bar = x;
上面代码中,由于变量foo和bar都等于x,而且x的值也没有发生变化,所以编译器可能会把x放入缓存,直接从缓存读取值,而不是从x的原始内存位置读取,然后对foo和bar进行赋值。如果x被设定为 volatile,编译器就不会把它放入缓存,每次都从原始位置去取x的值,因为在两次读取之间,其他程序可能会改变x。
restrict
restrict 说明符允许编译器优化某些代码。它只能用于指针,表明该指针是访问数据的唯一方式。
1
int* restrict pt = (int*) malloc(10 * sizeof(int));
下面例子中变量foo指向的内存,可以用foo访问,也可以用bar访问,因此就不能将foo设为 restrict。
1
2
int foo[10];
int* bar = foo;
restrict 用于函数参数时,表示参数的内存地址之间没有重叠。
1
2
3
4
5
6
void swap(int* restrict a, int* restrict b) {
int t;
t = *a;
*a = *b;
*b = t;
}
预处理指令
C 语言编译器在编译程序之前,会先使用预处理器(preprocessor)处理代码。
预处理器首先会清理代码,进行删除注释、多行语句合成一个逻辑行等工作。然后,执行#开头的预处理指令。
预处理指令可以出现在程序的任何地方,但是习惯上往往放在代码的开头部分,使得程序的可读性更好,也更容易修改。
每个预处理指令都以#开头,放在一行的行首,指令前面可以有空白字符(比如空格或制表符)。#和指令的其余部分之间也可以有空格,但是为了兼容老的编译器,一般不留空格。
所有预处理指令都是一行的,除非在行尾使用反斜杠,将其折行。指令结尾处不需要分号。
在代码编译前,预处理器会先处理预处理指令,根据指令的含义修改 C 语言代码。修改后的代码会被另存为中间文件或直接输入编译器中,而不会保存到源文件中。因此,预处理器不会改动源文件。
#define
#define是最常见的预处理指令,用来将指定的词替换成另一个词。它的参数分成两个部分,第一个参数就是要被替换的部分,其余参数是替换后的内容。每条替换规则,称为一个宏(macro)。宏是原样替换,指定什么内容,就一模一样替换成什么内容。
1
#define MAX 100 // 将源码里面的MAX,全部替换成100。
宏的名称不允许有空格,而且必须遵守 C 语言的变量命名规则,只能使用字母、数字与下划线,且首字符不能是数字。
#define指令从#开始,一直到换行符为止。如果整条指令过长,可以在折行处使用反斜杠,延续到下一行。
1
2
#define OW "C programming language is invented \
in 1970s."
#define允许多重替换,即一个宏可以包含另一个宏。
1
2
#define TWO 2
#define FOUR TWO*TWO // FOUR会被替换成2*2
如果宏出现在字符串里面(即出现在双引号中),或者是其他标识符的一部分,就会失效,并不会发生替换。
1
2
3
4
5
#define TWO 2
printf("TWO\n"); // 输出 TWO
const TWOs = 22;
printf("%d\n", TWOs); // 输出 22
带参数的宏
宏的强大之处在于,它的名称后面可以使用括号,指定接受一个或多个参数。
1
#define SQUARE(X) X*X
注意,宏的名称与左边圆括号之间,不能有空格。这个宏的用法如下。
1
z = SQUARE(2); // 替换成 z = 2*2;
这种写法很像函数,但又不是函数,而是完全原样的替换,会跟函数有不一样的行为。
1
2
3
#define SQUARE(X) X*X
printf("%d\n", SQUARE(3 + 4)); // 输出19,即3+4*3+4=19
原样替换可能导致意料之外的行为。解决办法就是在定义宏的时候,尽量多使用圆括号,这样可以避免很多意外。
1
2
3
#define SQUARE(X) ((X) * (X)) // 有两层圆括号,就可以避免很多错误的发生
printf("%d\n", SQUARE(3 + 4)); // 输出49,即(3+4)*(3+4)=49
宏的参数也可以是空的。这种情况其实可以省略圆括号,但是加上会让它看上去更像函数。
1
#define getchar() getc(stdin)
一般来说,带参数的宏都是一行的。下面是两个例子。
1
2
#define MAX(x, y) ((x)>(y)?(x):(y))
#define IS_EVEN(n) ((n)%2==0)
如果宏的长度过长,可以使用反斜杠\折行,将宏写成多行。把替换文本放在大括号里面,可以创造一个块作用域,避免宏内部的变量污染外部。
1
2
3
4
5
6
#define PRINT_NUMS_TO_PRODUCT(a, b) { \
int product = (a) * (b); \
for (int i = 0; i < product; i++) { \
printf("%d\n", i); \
} \
}
带参数的宏也可以嵌套,一个宏里面包含另一个宏。下面示例是一元二次方程组求解的宏,由于存在正负两个解,所以宏 QUAD 先替换成另外两个宏 QUADP 和 QUADM,后者再各自替换成一个解。
1
2
3
#define QUADP(a, b, c) ((-(b) + sqrt((b) * (b) - 4 * (a) * (c))) / (2 * (a)))
#define QUADM(a, b, c) ((-(b) - sqrt((b) * (b) - 4 * (a) * (c))) / (2 * (a)))
#define QUAD(a, b, c) QUADP(a, b, c), QUADM(a, b, c)
什么时候使用带参数的宏,什么时候使用函数呢?
一般来说,应该首先使用函数,它的功能更强、更容易理解。宏有时候会产生意想不到的替换结果,而且往往只能写成一行,除非对换行符进行转义,但是可读性就变得很差。
宏的优点是相对简单,本质上是字符串替换,不涉及数据类型,不像函数必须定义数据类型。而且,宏将每一处都替换成实际的代码,省掉了函数调用的开销,所以性能会好一些。另外,以前的代码大量使用宏,尤其是简单的数学运算,为了读懂前人的代码,需要对它有所了解。
#运算符,##运算符
由于宏不涉及数据类型,所以替换以后可能为各种类型的值。如果希望替换后的值为字符串,可以在替换文本的参数前面加上#。
1
2
#define STR(x) #x
printf("%s\n", STR(3.14159)); // 等同于 printf("%s\n", "3.14159");
上面示例中,STR(3.14159)会被替换成3.14159。如果x前面没有#,这会被解释成一个浮点数,有了#以后,就会被转换成字符串。
如果替换后的文本里面,参数需要跟其他标识符连在一起,组成一个新的标识符,可以使用##运算符。它起到粘合作用,将参数嵌入一个标识符之中。
1
2
3
4
5
#define MK_ID(n) i##n
int MK_ID(1), MK_ID(2), MK_ID(3);
// 替换成
int i1, i2, i3;
上面示例中,n是宏MK_ID的参数,这个参数需要跟标识符i粘合在一起,这时i和n之间就要使用##运算符。从这个例子可以看到,##运算符的一个主要用途是批量生成变量名和标识符。
不定参数的宏
宏的参数还可以是不定数量的,即不确定有多少个参数,...表示剩余的参数,且只能替代宏的尾部参数。
1
2
3
4
5
#define X(a, b, ...) (10*(a) + 20*(b)), __VA_ARGS__
X(5, 4, 3.14, "Hi!", 12)
// 替换成
(10*(5) + 20*(4)), 3.14, "Hi!", 12
上面示例中,X(a, b, ...)表示X()至少有两个参数,多余的参数使用...表示。在替换文本中,__VA_ARGS__代表多余的参数,每个参数之间使用逗号分隔。
__VA_ARGS__前面加上一个#号,可以让输出变成一个字符串。
1
2
#define X(...) #__VA_ARGS__
printf("%s\n", X(1,2,3)); // 输出 "1, 2, 3"
#undef
#undef指令用来取消已经使用#define定义的宏。
1
2
#define LIMIT 400
#undef LIMIT // 取消已经定义的宏LIMIT,后面就可以重新用 LIMIT 定义一个宏。
有时候想重新定义一个宏,但不确定是否以前定义过,就可以先用#undef取消,然后再定义。因为同名的宏如果两次定义不一样,会报错,而#undef的参数如果是不存在的宏,并不会报错。
GCC 的-U选项可以在命令行取消宏的定义,相当于#undef。如下所示,-U参数,取消了宏LIMIT,相当于源文件里面的#undef LIMIT。
1
$ gcc -ULIMIT foo.c
#include
#include指令用于编译时将其他源码文件,加载进入当前文件。它有两种形式。
- 文件名写在尖括号里面,表示该文件是系统提供的,通常是标准库的库文件,不需要写路径。因为编译器会到系统指定的安装目录里面,去寻找这些文件。
- 文件名写在双引号里面,表示该文件由用户提供,具体的路径取决于编译器的设置,可能是当前目录,也可能是项目的工作目录。如果所要包含的文件在其他位置,就需要指定路径。
1
2
3
4
5
6
7
// 形式一
#include <foo.h> // 加载系统提供的文件
// 形式二
#include "foo.h" // 加载用户提供的文件
#include "/usr/local/lib/foo.h" // 指定用户文件的路径
GCC 编译器的-I参数,也可以用来指定include命令中用户文件的加载路径。如下所示,-Iinclude/指定从当前目录的include子目录里面,加载用户自己的文件。
1
$ gcc -Iinclude/ -o code code.c
#include最常见的用途,就是用来加载包含函数原型的头文件。多个#include指令的顺序无关紧要,多次包含同一个头文件也是合法的。
#if…#endif
#if...#endif指令用于预处理器的条件判断,满足条件时,内部的行会被编译,否则就被编译器忽略。
#if后面的判断条件,通常是一个表达式。如果表达式的值不等于 0,就表示判断条件为真,编译内部的语句;如果表达式的值等于 0,表示判断条件为伪,则忽略内部的语句。
1
2
3
#if 0
const double pi = 3.1415; // 不会执行
#endif
上面示例中,#if后面的 0,表示判断条件不成立。所以,内部的变量定义语句会被编译器忽略。#if 0这种写法常用来当作注释使用,不需要的代码就放在#if 0里面。
#if...#endif之间还可以加入#else指令,用于指定判断条件不成立时,需要编译的语句。下面的示例中,宏FOO如果定义过,会被替换成 1,从而输出"defined",否则输出"not defined"。
1
2
3
4
5
6
#define FOO 1
#if FOO
printf("defined\n");
#else
printf("not defined\n");
#endif
如果有多个判断条件,还可以加入#elif命令。如下所示,通过#elif指定了第二重判断。注意,#elif的位置必须在#else之前。如果多个判断条件皆不满足,则执行#else的部分。
1
2
3
4
5
6
7
#if HAPPY_FACTOR == 0
printf("I'm not happy!\n");
#elif HAPPY_FACTOR == 1
printf("I'm just regular\n");
#else
printf("I'm extra happy!\n");
#endif
#if的常见应用就是打开(或关闭)调试模式。如下所示,通过将DEBUG设为 1,就打开了调试模式,可以输出调试信息。
1
2
3
4
5
#define DEBUG 1
#if DEBUG
printf("value of i : %d\n", i);
printf("value of j : %d\n", j);
#endif
GCC 的-D参数可以在编译时指定宏的值,因此可以很方便地打开调试开关。 如下所示,-D参数指定宏DEBUG为 1,相当于在代码中指定#define DEBUG 1。
1
$ gcc -DDEBUG=1 foo.c
#ifdef…#endif
#ifdef...#endif指令用于判断某个宏是否定义过。
有时源码文件可能会重复加载某个库,为了避免这种情况,可以在库文件里使用#define定义一个空的宏。通过这个宏,判断库文件是否被加载了。如下所示,ifdef检查宏EXTRA_HAPPY是否定义过。如果已经存在,表示加载过库文件,就会打印一行提示。
1
2
3
4
5
#define EXTRA_HAPPY
#ifdef EXTRA_HAPPY
printf("I'm extra happy!\n");
#endif
#ifdef可以与#else指令配合使用,用来实现条件编译。如下所示,通过判断宏MAVIS是否定义过,实现加载不同的头文件。
1
2
3
4
5
6
7
8
#ifdef MAVIS
#include "foo.h"
#define STABLES 1
#else
#include "bar.h"
#define STABLES 2
#endif
defined 运算符
defined是一个预处理运算符,如果它的参数是一个定义过的宏,就会返回 1,否则返回 0。上一节的#ifdef指令,等同于#if defined。
使用defined运算符,可以完成多重判断。
1
2
3
4
5
#if defined FOO
x = 2;
#elif defined BAR
x = 3;
#endif
defined运算符的最常见应用,就是对于不同架构的系统,加载不同的头文件。如下所示,不同架构的系统需要定义对应的宏。代码根据不同的宏,加载对应的头文件。
1
2
3
4
5
6
7
8
9
10
#if defined IBMPC
#include "ibmpc.h"
#elif defined MAC
#include "mac.h"
#else
#include "general.h"
#endif
#ifndef…#endif
#ifndef...#endif指令跟#ifdef...#endif正好相反。它用来判断,如果某个宏没有被定义过,则执行指定的操作。#ifndef等同于#if !defined。
1
2
3
4
5
6
7
#ifdef EXTRA_HAPPY
printf("I'm extra happy!\n");
#endif
#ifndef EXTRA_HAPPY
printf("I'm just regular\n");
#endif
#ifndef常用于防止重复加载。举例来说,为了防止头文件myheader.h被重复加载,可以把它放在#ifndef...#endif里面加载。
1
2
3
4
#ifndef MYHEADER_H
#define MYHEADER_H
#include "myheader.h"
#endif
上面示例中,宏MYHEADER_H对应文件名myheader.h的大写。只要#ifndef发现这个宏没有被定义过,就说明该头文件没有加载过,从而加载内部的代码,并会定义宏MYHEADER_H,防止被再次加载。
预定义宏
C 语言提供一些预定义的宏,可以直接使用。
| DATE | 编译日期,格式为Mmm dd yyyy的字符串 |
|---|---|
| TIME | 编译时间,格式为hh:mm:ss |
| FILE | 当前文件名 |
| LINE | 当前行号 |
| func | 当前正在执行的函数名,该预定义宏必须在函数作用域使用 |
| STDC | 如果被设为 1,表示当前编译器遵循 C 标准 |
| STDC_HOSTED | 如果被设为 1,表示当前编译器可以提供完整的标准库;否则被设为 0(嵌入式系统的标准库常常是不完整的) |
| STDC_VERSION | 编译所使用的 C 语言版本,是一个格式为 yyyymmL 的长整数,C99 版本为199901L,C11 版本为201112L,C17 版本为201710L |
下面示例打印这些预定义宏的值。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
#include <stdio.h>
int main(void) {
printf("This function: %s\n", __func__);
printf("This file: %s\n", __FILE__);
printf("This line: %d\n", __LINE__);
printf("Compiled on: %s %s\n", __DATE__, __TIME__);
printf("C Version: %ld\n", __STDC_VERSION__);
}
/* 输出如下
This function: main
This file: test.c
This line: 7
Compiled on: Mar 29 2021 19:19:37
C Version: 201710
*/
#line
#line指令用于覆盖预定义宏__LINE__,将其改为自定义的行号。后面的行将从__LINE__的新值开始计数。此外,#line还可以改掉预定义宏__FILE__,将其改为自定义的文件名。
如下所示,紧跟在#line 300后面一行的行号将被改成 300,其后的行会在 300 的基础上递增编号,而且文件名重置为newfilename。
1
#line 300 "newfilename"
#error
#error指令用于让预处理器抛出一个错误,终止编译。
1
2
3
#if __STDC_VERSION__ != 201112L
#error Not C11
#endif
上面示例指定,如果编译器不使用 C11 标准,就中止编译。比如,使用 C99 标准编译,GCC 编译器会像下面这样报错。
1
2
$ gcc -std=c99 newish.c
newish.c:14:2: error: #error Not C11
#error指令也可以用在#if...#elif...#else的部分。
1
2
3
4
5
6
7
8
9
#if defined WIN32
// ...
#elif defined MAC_OS
// ...
#elif defined LINUX
// ...
#else
#error NOT support the operating system
#endif
#pragma
#pragma指令用来修改编译器属性。
1
2
#pragma c9x on // 使用 C99 标准
#pragma once // 编译器这个头文件只需要被包含一次。如果已经包含过,就不再重复包含
#pragma指令还可以用来指定结构体的对齐方式。改变数据类型的,直接效果对齐方式最大的好处就是减少占用的内存,但是程序性能会有一定下降,即用时间换空间。
1
2
3
4
5
#pragma pack(n) // 按照n个字节对齐
#pragma pack() // 取消自定义字节对齐方式
#pragma pack(push,1) // 把当前对齐方式压栈,并设新的对齐方式为按1个字节对齐
#pragma pack(pop) // 恢复栈内保存的对齐方式,即上一步push压栈的对齐方式
下面是一个代码示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
#pragma pack(push,1)
typedef struct
{
boolean suLinkStatusIsOk:1;
boolean muFatalErrorOccured:1;
boolean transactionIsOnGoing:1;
boolean tamperingIsDetected:1;
boolean timeSyncStatusIsOk:1;
boolean overTemperatureIsDetected:1;
boolean reversedVoltage:1;
boolean suMeasureFailureOccurred:1;
}StatusData_status_t;
typedef struct
{
boolean muInitIsFailed:1;
boolean suStateIsInvalid:1;
boolean versionCheckIsFailed:1;
boolean muRngInitIsFailed:1;
boolean muDataIntegrityIsFailed:1;
boolean muFwIntegrityIsFailed:1;
boolean suIntegrityIsFailed:1;
boolean logbookIntegrityIsFailed:1;
boolean logbookIsFull:1;
boolean memoryAccessIsFailed:1;
boolean muStateIsFailed:1;
}StatusData_errors_t;
#pragma pack(pop)
上面的代码中首先将原来的对齐方式压栈,并制定新的对齐方式为按 1 个字节对齐,结束后重新恢复原来的对齐方式。因此,第一个结构体占了 1 个字节,第二个结构体占了 2 个字节(后 5 位用 0 补齐),共需要消耗 3 个字节。不这么做的话,这两个结构体包含 19 个char类型的变量,每个 1 个字节,共需要消耗 19 个字节。
多文件项目
一个软件项目往往包含多个源码文件,编译时需要将这些文件一起编译,生成一个可执行文件。
假定一个项目有两个源码文件 foo.c 和 bar.c,其中 foo.c 是主文件,bar.c 是库文件。所谓主文件,就是包含了main()函数的项目入口文件,里面会引用库文件定义的各种函数。
1
2
3
4
5
#include <stdio.h>
int main(void) {
printf("%d\n", add(2, 3)); // 5!
}
1
2
3
int add(int x, int y) {
return x + y;
}
现在,将这两个文件一起编译。
1
2
3
4
$ gcc -o foo foo.c bar.c
# 更省事的写法
$ gcc -o foo *.c
gcc 的-o参数指定生成的二进制可执行文件的文件名,本例是 foo。
这个命令运行后,编译器会发出警告,原因是在编译 foo.c 的过程中,编译器发现一个不认识的函数add(),foo.c 里面没有这个函数的原型或者定义。因此,最好修改一下 foo.c,在文件头部加入add()的函数原型。
1
2
3
4
5
6
#include <stdio.h>
int add(int, int);
int main(void) {
printf("%d\n", add(2, 3)); // 5!
}
如果有多个文件都使用这个函数add(),那么每个文件都需要加入函数原型。一旦需要修改函数add()(比如改变参数的数量),就会非常麻烦,需要每个文件逐一改动。所以,通常的做法是新建一个专门的头文件 bar.h,放置所有在 bar.c 里面定义的函数的原型。
1
int add(int, int);
然后使用include命令,在用到这个函数的源码文件里面加载这个头文件 bar.h。
1
2
3
4
5
6
#include <stdio.h>
#include "bar.h" // 双引号表示它是用户提供的;没有写路径表示与当前源码文件在同一个目录。
int main(void) {
printf("%d\n", add(2, 3)); // 5!
}
然后,最好在 bar.c 里面也加载这个头文件,这样可以让编译器验证,函数原型与函数定义是否一致。
1
2
3
4
5
#include "bar.h"
int add(int a, int b) {
return a + b;
}
现在重新编译,就可以顺利得到二进制可执行文件。
1
2
$ gcc -o foo foo.c bar.c
$ ./foo # 执行编译好的程序
头文件守卫
头文件里面还可以加载其他头文件,因此有可能产生重复加载。比如,a.h 和 b.h 都加载了 c.h,然后 foo.c 同时加载了 a.h 和 b.h,这意味着 foo.c 会编译两次 c.h。
最好避免这种重复加载,虽然多次定义同一个函数原型并不会报错,但是有些语句重复使用会报错,比如多次重复定义同一个 Struct 数据结构。
解决重复加载的常见方法是,在头文件里面设置一个专门的宏,加载时一旦发现这个宏存在,就不再继续加载当前文件了。这种做法也被称为头文件守卫。
1
2
3
4
#ifndef BAR_H
#define BAR_H
int add(int, int);
#endif
上面示例中,头文件 bar.h 使用#ifndef和#endif设置了一个条件判断。每当加载这个头文件时,就会执行这个判断,查看有没有设置过宏BAR_H。如果设置过了,表明这个头文件已经加载过了,就不再重复加载了,反之就先设置一下这个宏,然后加载函数原型。
extern 说明符
当前文件还可以使用其他文件定义的变量,这时要使用 extern 说明符,在当前文件中声明这个变量是其他文件定义的。
如下所示,extern 说明符告诉编译器,变量 myvar 是其他脚本文件声明的,不需要在这里为它分配内存空间。由于不需要分配内存空间,所以 extern 声明数组时,不需要给出数组长度。
1
2
extern int myVar;
extern int a[];
这种共享变量的声明,可以直接写在源码文件里面,也可以放在头文件中,通过#include指令加载。
static 说明符
正常情况下,当前文件内部的全局变量,可以被其他文件使用。有时候,不希望发生这种情况,而是希望某个变量只局限在当前文件内部使用,不要被其他文件引用。
这时可以在声明变量的时候,使用 static 关键字,使得该变量变成当前文件的私有变量。
1
static int foo = 3; //变量foo只能在当前文件里面使用,其他文件不能引用。
编译策略
多个源码文件的项目,编译时需要所有文件一起编译。哪怕只是修改了一行,也需要从头编译,非常耗费时间。
为了节省时间,通常的做法是将编译拆分成两个步骤。
- 使用 GCC 的
-c参数,将每个源码文件单独编译为对象文件(object file)。 - 将所有对象文件链接在一起,合并生成一个二进制可执行文件。
1
2
3
4
5
$ gcc -c foo.c # 生成对象文件 foo.o
$ gcc -c bar.c # 生成对象文件 bar.o
# 更省事的写法
$ gcc -c *.c
对象文件不是可执行文件,只是编译过程中的一个阶段性产物,文件名与源码文件相同,但是后缀名变成了.o。
得到所有的对象文件以后,再次使用 gcc 命令,将它们通过链接,合并生成一个可执行文件。
1
2
3
4
$ gcc -o foo foo.o bar.o
# 更省事的写法
$ gcc -o foo *.o
之后,修改了哪一个源文件,就将这个文件重新编译成对象文件,其他文件不用重新编译,可以继续使用原来的对象文件,最后再将所有对象文件重新链接一次就可以了。
由于链接的耗时大大短于编译,这样做就节省了大量时间。
make 命令
大型项目的编译,如果全部手动完成,是非常麻烦的,容易出错。一般会使用专门的自动化编译工具,比如 make。
make 是一个命令行工具,使用时会自动在当前目录下搜索配置文件 makefile(也可以写成 Makefile)。该文件定义了所有的编译规则,每个编译规则对应一个编译产物。为了得到这个编译产物,它需要知道两件事:
- 依赖项(生成该编译产物,需要用到哪些文件)
- 生成命令(生成该编译产物的命令)
比如,对象文件 foo.o 是一个编译产物,它的依赖项是 foo.c,生成命令是gcc -c foo.c。对应的编译规则如下:
1
2
foo.o: foo.c
gcc -c foo.c
上面示例中,编译规则由两行组成。第一行首先是编译产物,冒号后面是它的依赖项,第二行则是生成命令。
注意,第二行的缩进必须使用 Tab 键,如果使用空格键会报错。
完整的配置文件 makefile 由多个编译规则组成,可能是下面的样子,它包含三个编译规则,对应三个编译产物(foo、foo.o 和 bar.o),每个编译规则之间使用空行分隔。
1
2
3
4
5
6
7
8
foo: foo.o bar.o
gcc -o foo foo.o bar.o
foo.o: bar.h foo.c
gcc -c foo.c
bar.o: bar.h bar.c
gcc -c bar.c
有了 makefile,编译时,只要在 make 命令后面指定编译目标(编译产物的名字),就会自动调用对应的编译规则,根据不同的命令,生成不同的编译产物。
1
2
3
4
5
$ make foo
# or
$ make foo.o
# or
$ make bar.o
如果省略了编译目标,make 命令会执行第一条编译规则,构建相应的产物。
1
$ make
make 后面没有编译目标,所以会执行 makefile 的第一条编译规则,本例是make foo。由于用户期望执行 make 后得到最终的可执行文件,所以建议总是把最终可执行文件的编译规则,放在 makefile 文件的第一条。makefile 本身对编译规则没有顺序要求。
make 命令的强大之处在于,它不是每次执行命令,都会进行编译,而是会检查是否有必要重新编译。具体方法是,通过检查每个源码文件的时间戳,确定在上次编译之后,哪些文件发生过变动。然后,重新编译那些受到影响的编译产物(即编译产物直接或间接依赖于那些发生变动的源码文件),不受影响的编译产物,就不会重新编译。
举例来说,上次编译之后,修改了 foo.c,没有修改 bar.c 和 bar.h。于是,重新运行make foo命令时,Make 就会发现 bar.c 和 bar.h 没有变动过,因此不用重新编译 bar.o,只需要重新编译 foo.o。有了新的 foo.o 以后,再跟 bar.o 一起,重新编译成新的可执行文件 foo。
Make 这样设计的最大好处,就是自动处理编译过程,只重新编译变动过的文件,因此大大节省了时间。
命令行环境
命令行参数
C 语言程序可以从命令行接收参数。
1
$ ./foo hello world # foo程序接收了两个命令行参数hello和world
程序内部怎么拿到命令行参数呢?C 语言会把命令行输入的内容,放在一个数组里面。main()函数的参数可以接收到这个数组。
1
2
3
4
5
6
7
#include <stdio.h>
int main(int argc, char* argv[]) {
for (int i = 0; i < argc; i++) {
printf("arg %d: %s\n", i, argv[i]);
}
}
上面示例中,main()函数有两个参数 argc(argument count)和 argv(argument variable)。这两个参数的名字可以任意取,但是一般来说,约定俗成就是使用这两个词。
- 参数 argc 是命令行参数的数量,由于程序名也被计算在内,所以严格地说 argc 是参数数量 + 1。
- 参数 argv 是一个数组,保存了所有的命令行输入,它的每个成员是一个字符串指针。
以上面的./foo hello world为例,argc是 3,表示命令行输入有三个组成部分:./foo、hello、world。数组argv用来获取这些输入,argv[0]是程序名./foo,argv[1]是 hello,argv[2]是 world。一般来说,argv[1]到argv[argc-1]依次是命令行的所有参数。argv[argc]则是一个空指针 NULL。
由于字符串指针可以看成是字符数组,所以下面三种写法是等价的。
1
2
3
4
5
6
// 写法一
int main(int argc, char* argv[])
// 写法二
int main(int argc, char** argv)
// 写法三
int main(int argc, char argv[][])
利用argc,可以限定函数只能有多少个参数。如下所示,argc不等于 3 就会报错,这样就限定了程序必须有两个参数,才能运行。
1
2
3
4
5
6
7
8
9
#include <stdio.h>
int main(int argc, char** argv) {
if (argc != 3) {
printf("usage: mult x y\n");
return 1;
}
printf("%d\n", atoi(argv[1]) * atoi(argv[2]));
return 0;
}
另外,由于argv数组的最后一个成员是 NULL 指针,可以利用这一特性进行参数的遍历:
1
2
3
for (char** p = argv; *p != NULL; p++) {
printf("arg: %s\n", *p);
}
由于argv的地址是固定的,不能执行自增运算argv++,所以必须通过一个中间变量p,完成遍历操作。
退出状态
C 语言规定,如果main()函数没有return语句,那么结束运行的时候,默认会添加一句return 0,即返回整数 0,表示程序运行成功。如果返回非零值,就表示程序运行出了问题。
Bash 的环境变量$?可以用来读取上一个命令的返回值,从而知道是否运行成功。
1
2
3
$ ./foo hello world
$ echo $? # 打印环境变量$?的值
0
注意,只有main()会默认添加return 0,其他函数都没有这个机制。
环境变量
C 语言提供了getenv()函数,用来读取命令行环境变量。函数原型定义在头文件stdlib.h中。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
#include <stdio.h>
#include <stdlib.h>
int main(void) {
char* val = getenv("HOME"); // 获取命令行的环境变量$HOME
if (val == NULL) {
printf("Cannot find the HOME environment variable\n");
return 1;
}
printf("Value: %s\n", val);
return 0;
}
多字节字符
Unicode
C 语言诞生时,只考虑了英语字符,使用 7 位的 ASCII 码表示所有字符。ASCII 码的范围是 0 到 127,也就是 100 多个字符,所以 char 类型只占用一个字节。
但是,如果处理非英语字符,一个字节就不够了,单单是中文,就至少有几万个字符,字符集就势必使用多个字节表示。
最初,不同国家有自己的字符编码方式,这样不便于多种字符的混用。因此,后来就逐渐统一到 Unicode 编码,将所有字符放入一个字符集。
Unicode 为每个字符提供一个号码,称为码点(code point),其中 0 到 127 的部分,跟 ASCII 码是重合的。通常使用U+十六进制码点表示一个字符,比如U+0041表示字母A。
Unicode 编码目前一共包含了 100 多万个字符,码点范围是 U+0000 到 U+10FFFF。完整表达整个 Unicode 字符集,至少需要三个字节。但是,并不是所有文档都需要那么多字符,比如对于 ASCII 码就够用的英语文档,如果每个字符使用三个字节表示,就会比单字节表示的文件体积大出三倍。
为了适应不同的使用需求,Unicode 标准委员会提供了三种不同的表示方法,表示 Unicode 码点。
- UTF-8:使用 1 个到 4 个字节,表示一个码点。不同的字符占用的字节数不一样。
- UTF-16:对于
U+0000到U+FFFF的字符(称为基本平面),使用 2 个字节表示一个码点。其他字符使用 4 个字节。 - UTF-32:统一使用 4 个字节,表示一个码点。
其中,UTF-8的使用最为广泛,因为对于 ASCII 字符(U+0000到U+007F),它只使用一个字节表示,这就跟 ASCII 的编码方式完全一样。
C 语言提供了两个宏,表示当前系统支持的编码字节长度。这两个宏都定义在头文件limits.h。
- MB_LEN_MAX:任意支持地区的最大字节长度,定义在
limits.h。 - MB_CUR_MAX:当前语言的最大字节长度,总是小于或等于 MB_LEN_MAX,定义在
stdlib.h。
字符的表示方法
字符表示法的本质,是将每个字符映射为一个整数,然后从编码表获得该整数对应的字符。
C 语言提供了不同的写法,用来表示字符的整数号码。
\123:以八进制值表示一个字符,斜杠后面需要三个数字。\x4D:以十六进制表示一个字符,\x后面是十六进制整数。\u2620:以 Unicode 码点表示一个字符(不适用于 ASCII 字符),码点以十六进制表示,\u后面需要 4 个字符。\U0001243F:以 Unicode 码点表示一个字符(不适用于 ASCII 字符),码点以十六进制表示,\U后面需要 8 个字符。
1
2
3
4
5
6
7
8
// 下面三行都会输出"ABC"
printf("ABC\n");
printf("\101\102\103\n");
printf("\x41\x42\x43\n");
// 下面两行都会输出"• Bullet 1"
printf("\u2022 Bullet 1\n");
printf("\U00002022 Bullet 1\n");
多字节字符的表示
C 语言预设只有基本字符,才能使用字面量表示,其它字符都应该使用码点表示,并且当前系统还必须支持该码点的编码方法。
所谓基本字符,指的是所有可打印的 ASCII 字符,但是有三个字符除外:@、$、```。
因此,遇到非英语字符,应该将其写成 Unicode 码点形式。
1
2
char* s = "\u6625\u5929";
printf("%s\n", s); // 输出中文"春天"
如果当前系统是 UTF-8 编码,可以直接用字面量表示多字节字符。
1
2
char* s = "春天";
printf("%s\n", s);
注意,\u + 码点和\U + 码点的写法,不能用来表示 ASCII 码字符(码点小于0xA0的字符),只有三个字符除外:0x24表示$,0x40表示@和0x60表示```。
1
2
char* s = "\u0024\u0040\u0060";
printf("%s\n", s); // 输出"@$`"
为了保证程序执行时,字符能够正确解读,最好将程序环境切换到本地化环境。如下所示,使用setlocale()切换执行环境到系统的本地化语言。setlocale()的原型定义在头文件locale.h
1
setlocale(LC_ALL, "");
也可以像下面这样,指定编码语言。
1
setlocale(LC_ALL, "zh_CN.UTF-8"); //将程序执行环境,切换到中文环境的 UTF-8 编码。
C 语言允许使用u8前缀,对多字节字符串指定编码方式为 UTF-8。
1
2
char* s = u8"春天";
printf("%s\n", s);
一旦字符串里面包含多字节字符,就意味着字符串的字节数与字符数不再一一对应了。比如,字符串的长度为 10 字节,就不再是包含 10 个字符,而可能只包含 7 个字符、5 个字符等等。如下所示,字符串s只包含两个字符,但是strlen()返回的结果却是 6,表示这两个字符一共占据了 6 个字节。
1
2
3
4
setlocale(LC_ALL, "");
char* s = "春天";
printf("%d\n", strlen(s)); // 6
C 语言的字符串函数只针对单字节字符有效,对于多字节字符都会失效,比如strtok()、strchr()、strspn()、toupper()、tolower()、isalpha()等不会得到正确结果。
宽字符
上面提到的多字节字符串,每个字符的字节宽度是可变的。这种编码方式虽然使用起来方便,但是很不利于字符串处理,因此必须逐一检查每个字符占用的字节数。所以除了这种方式,C 语言还提供了确定宽度的多字节字符存储方式,称为宽字符(wide character)。
所谓宽字符,就是每个字符占用的字节数是固定的,要么是 2 个字节,要么是 4 个字节。
宽字符有一个单独的数据类型wchar_t,每个宽字符都是这个类型。它属于整数类型的别名,可能是有符号的,也可能是无符号的,由当前实现决定。该类型的长度为 16 位(2 个字节)或 32 位(4 个字节),足以容纳当前系统的所有字符。它定义在头文件wchar.h里面。
宽字符的字面量必须加上前缀L,否则 C 语言会把字面量当作窄字符类型处理。
1
2
3
4
5
6
7
setlocale(LC_ALL, "");
wchar_t c = L'牛'; //L在单引号前面,表示宽字符,对应printf的占位符为%lc
printf("%lc\n", c);
wchar_t* s = L"春天";
printf("%ls\n", s); //L在双引号前面,表示宽字符串,对应printf的占位符为%ls
宽字符串的结尾也有一个空字符,不过是宽空字符,占用多个字节。
处理宽字符,需要使用宽字符专用的函数,绝大部分都定义在头文件wchar.h。
多线程
多线程操作
- process:一个在内存中运行的应用程序。每个进程都有自己独立的一块内存空间,一个进程可以有多个线程
- thread:进程中的一个执行任务,负责当前进程中程序的执行。一个进程至少有一个线程,一个进程可以运行多个线程,多个线程可共享数据。
需要#include <pthread.h>来使用 C 语言中的线程,参考教程:b 站正月点灯笼视频
注意使用多线程编程时,需要给编译语句加-lpthread参数,例如gcc thread1.c -lpthread -o thread1
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
// 线程函数,返回值和参数类型必须为void*,代表任意类型的指针
void* myfunc(void* args) {
printf("Hello world.\n");
return NULL;
}
int main() {
pthread_t th; //声明一个线程变量
pthread_create(&th, NULL, myfunc, NULL); //创建一个线程,共4个参数,第一个是线程的地址,第二个用不到,第三个是线程要运行的函数, 第四个是函数的参数
pthread_join(th, NULL); //等待线程结束,共2个参数,第一个是线程,第二个用不到
return 0;
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
void* myfunc(void* args) {
char* s = (char*) args; //强制转换成字符串类型
for (int i = 0; i < 50; i++) {
printf("%s: %d.\n", s, i);
}
return NULL;
}
int main() {
pthread_t th1;
pthread_t th2;
pthread_create(&th1, NULL, myfunc, "th1"); //通过第4个参数给线程传递参数
pthread_create(&th2, NULL, myfunc, "th2");
pthread_join(th1, NULL);
pthread_join(th2, NULL);
return 0;
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
int arr[5000];
typedef struct {
int first;
int last;
int result;
} MY_ARGS; //创建一个结构体用于给线程函数传递参数
void* myfunc(void* args) {
MY_ARGS* my_args = (MY_ARGS*) args; //不要忘记强制类型转换
for (int i = my_args->first; i < my_args->last; i++) {
my_args->result = my_args->result + arr[i];
}
return NULL;
}
int main() {
for (int i = 0; i < 5000; i++) {
arr[i] = rand() % 50; // rand可以产生一个0-0x7fff的随机数,即最大是32767的一个数
}
pthread_t th1;
pthread_t th2;
MY_ARGS args1 = {0, 2500, 0}; // 对结构体进行初始化,第一组参数用于计算数组的前半段
MY_ARGS args2 = {2500, 5000, 0}; // 第二组参数用于计算数组的后半段
pthread_create(&th1, NULL, myfunc, &args1); // 第4个参数是指针,所以需要传递机构体的地址
pthread_create(&th2, NULL, myfunc, &args2);
pthread_join(th1, NULL);
pthread_join(th2, NULL);
printf("first half: %d\n", args1.result);
printf("last half: %d\n", args2.result);
printf("total sum: %d\n", args1.result + args2.result);
return 0;
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
int s = 0;
void* myfunc(void* args) {
for (int i = 0; i < 1000000; i++) {
s++;
}
}
int main() {
pthread_t th1;
pthread_t th2;
pthread_create(&th1, NULL, myfunc, NULL);
pthread_create(&th2, NULL, myfunc, NULL);
pthread_join(th1, NULL);
pthread_join(th2, NULL);
printf("result: %d", s);
return 0;
}
//输出结果:result: 1014806,不等于 2000000
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
pthread_mutex_t lock; //创建一个线程锁变量
int s = 0;
void* myfunc(void* args) {
for (int i = 0; i < 1000000; i++) {
pthread_mutex_lock(&lock); // 使用线程锁,线程锁是用来锁一段代码,而不是某个变量
s++;
pthread_mutex_unlock(&lock); // 解开线程锁
}
}
int main() {
pthread_t th1;
pthread_t th2;
pthread_mutex_init(&lock, NULL); //对线程锁进行初始化
pthread_create(&th1, NULL, myfunc, NULL);
pthread_create(&th2, NULL, myfunc, NULL);
pthread_join(th1, NULL);
pthread_join(th2, NULL);
printf("result: %d", s);
return 0;
}
//输出结果:result: 2000000
添加线程锁之后,可以得到正确的结果,但是需要注意的是,加锁和解锁的过程是需要消耗时间的,如果在循环内部频繁的进行加锁和解锁操作,会提高程序运行时间,导致程序运行效率降低。
假共享
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
#define MAX_LENGTH 5000000
typedef struct {
int first;
int last;
int id;
} MY_ARGS;
int* arr; //创建一个int指针,用于后续动态分配内存空间
int results[2]; // 存在假共享的问题
void* myfunc(void* args) {
MY_ARGS* my_args = (MY_ARGS*) args;
int first = my_args->first;
int last = my_args->last;
int id = my_args->id;
for (int i = first; i < last; i++) {
results[id] = results[id] + arr[i];
}
return NULL;
}
int main() {
arr = malloc(sizeof(int) * MAX_LENGTH); // 为该指针分配一个长度为max length的内存空间,用于存储数据,采用这种方法,可以生成动态数组。
for (int i = 0; i < MAX_LENGTH; i++) {
arr[i] = rand() % 5;
}
pthread_t th1;
pthread_t th2;
int mid = MAX_LENGTH / 2;
MY_ARGS args1 = {0, mid, 0};
MY_ARGS args2 = {mid, MAX_LENGTH, 1};
pthread_create(&th1, NULL, myfunc, &args1);
pthread_create(&th2, NULL, myfunc, &args2);
pthread_join(th1, NULL);
pthread_join(th2, NULL);
printf("result: %d", results[0] + results[1]);
return 0;
}
在 C 语言中,假共享常见于多个线程在不同核心上修改同一个缓存行中的不同变量时发生。
多线程代码为了充分利用 CPU 的资源,每个线程会在不同的核内运行,并且每个核都会维持自己的缓存区。由于线程的并发性,导致某个核的缓存数据发生变化时,其他核内的线程无法感知这种变化,最终在把数据写回主线程的时候会面临数据同步的问题,造成额外的时间消耗。
假共享一般出现在运算结果被保存在距离比较近的内存地址,且存在多核运算的场景,例如&results[0]和&results[1]。
解决假共享的方法之一是通过 padding 来调整变量在内存中的位置,使得不同变量不再共享同一缓存行。例如可以把 results 的长度改成 100,然后第二个 id 放在 results 尾端,由于 results 很长,整个 results 数组无法直接放入 CPU 缓存,而是被分成两段,这样就不会出现假共享的问题。
另一种方法是在修改变量时使用互斥量加锁,但这会导致线程间的锁竞争,降低程序执行效率。
标准库
类型和宏
stdlib.h定义了下面的类型别名。
- size_t:sizeof() 函数的返回类型。
- wchar_t:宽字符类型。
- div_t, ldiv_t, lldiv_t:div() 函数,ldiv() 函数和 lldiv() 函数的返回类型,其定义如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
int quot; // 商
int rem; // 余数
typedef struct {
int quot, rem;
} div_t;
typedef struct {
long int quot, rem;
} ldiv_t;
typedef struct {
long long int quot, rem;
} lldiv_t;
stdlib.h定义了下面的宏。
- NULL:空指针。
- EXIT_SUCCESS:函数运行成功时的退出状态。
- EXIT_FAILURE:函数运行错误时的退出状态。
- RAND_MAX:rand() 函数可以返回的最大值,通常等于 INT_MAX。
- MB_CUR_MAX:当前语言环境中,多字节字符占用的最大字节数。
常用函数
很多数学函数的参数值是 int 类型,但是同时提供 long int 类型与 long long int 类型的版本,比如abs()函数就还有labs()和llabs()版本。
| 函数 | 描述 |
|---|---|
| abs(x), labs(x), llabs(x) | 计算整数的绝对值 |
| div(x, y), ldiv(x, y), lldiv(x, y) | 计算两个整数的商和余数,返回一个结构体 |
| atoi(nums), atof(nums), atol(nums), atoll(nums) | 字符串数字部分转数值,ASCII to int |
| strtof(nums, &endptr), strtod(), strtold() | 字符串数字部分转数值,带指针 |
| strtol(nums, &endptr, base), strtoll(), strtoul(), strtoull() | 字符串数字部分转数值,带指针和进制 |
| rand() | 生成 0 ~ RAND_MAX 之间的随机整数 |
| srand(seed) | 设置 rand()函数的种子值 |
| abort() | 不正常地终止一个正在执行的程序 |
| exit(status),quick_exit(),_Exit(), | 以 status 退出当前正在执行的程序 |
| atexit(func),at_quick_exit() | 登记当前程序退出时所要执行的其他函数 |
| getenv(“PATH”) | 获取环境变量的值 |
| system(“ls -l”) | 让 OS 的命令处理器来执行传入的命令 |
| malloc(), calloc(), realloc(), free() | 内存管理函数 |
| qsort(base, nums, size, compar) | 快速排序一个数组 |
| bsearch(key, base, nitems, size, compar) | 用二分法在数组中搜索一个值 |
1
2
3
4
5
6
7
div_t d = div(64, -7);
// 输出 64 / -7 = -9
printf("64 / -7 = %d\n", d.quot);
// 输出 64 % -7 = 1
printf("64 %% -7 = %d\n", d.rem);
数学运算库
类型和宏
math.h 新定义了两个类型别名。
- float_t:(当前系统)最有效执行 float 运算的类型,宽度至少与 float 一样。
- double_t:(当前系统)最有效执行 double 运算的类型,宽度至少与 double 一样。
math.h 还定义了一些宏。
INFINITY:表示正无穷,返回一个 float 类型的值。NAN:表示非数字(Not-A-Number),返回一个 float 类型的值。
常用函数
很多数学函数的返回值是 double 类型,但是同时提供 float 类型与 long double 类型的版本,比如pow()函数就还有powf()和powl()版本。
| 函数 | 描述 |
|---|---|
| isfinite(x), isinf(x), isnan(x), isnormal(x) | 判断函数 |
| sin(a), cos(a), tan(a), asin(y), acos(x), atan(r), atan2(r) | 三角函数 |
| sinh(a), cosh(a), tanh(a), asinh(y), acosh(x), atanh(r) | 双曲函数 |
| sqrt(x), log(x), log10(x), exp(p), pow(base, p) | 数学函数 |
| round(x), trunc(), ceil(x), floor(x), fabs(x) | 取值函数 |
| fmin(a, b), fmax(a, b) | 求两者中最大/小值 |
| fmod(x, y) | %的浮点数版本,%只能用于整数运算 |
求绝对值函数abs(x)和fabs(x)的区别:
abs(x)包含在头文件中,参数和返回值都是 int 型。 fabs(x)包含在头文件中,参数可以是整型或 double 型,输出是 double 型。
APPENDIX
C 语言教程 - 《阮一峰《C 语言教程》》 - 书栈网 · BookStack
i++和++i的区别
1
2
3
4
5
6
7
8
9
10
11
12
//重载++运算符
iterator operator++(int) // it++,后缀递增运算符
{
iterator tmp = *this; // 先存住递增前的对象
pt = pt->next;
return tmp; // 返回递增前的对象
}
iterator operator++() // ++it,前缀递增运算符
{
pt = pt->next;
return *this; // 返回递增后的对象
}
后置++要多生成一个局部对象tmp,因此执行速度比前置的慢。同理,迭代器是一个对象,STL 在重载迭代器的++运算符时,后置形式也比前置形式慢。
在次数很多的循环中,++i 和 it+可能就会造成运行时间上可观的差别了。因此,对循环控制变量 i,要养成写++i、不写i++的习惯。
_t后缀的使用
后缀_t意味着 type/typedef(类型),是一种命名规范,类似于全局变量加前缀g_,主要被定义在头文件stdint.h中。
不推荐在自己的代码中使用:自定义的类型名如果加上后缀_t,则有可能与引入库中的类型命名冲突导致错误,因此不建议在自定义的类型名加上后缀_t。
自定义类型推荐的命名规范:自定义类型名加上相关的公司或项目前缀,如qq_int;也有人用_type作为后缀,如int_type;结合前两项,可以使用qq_int_type。