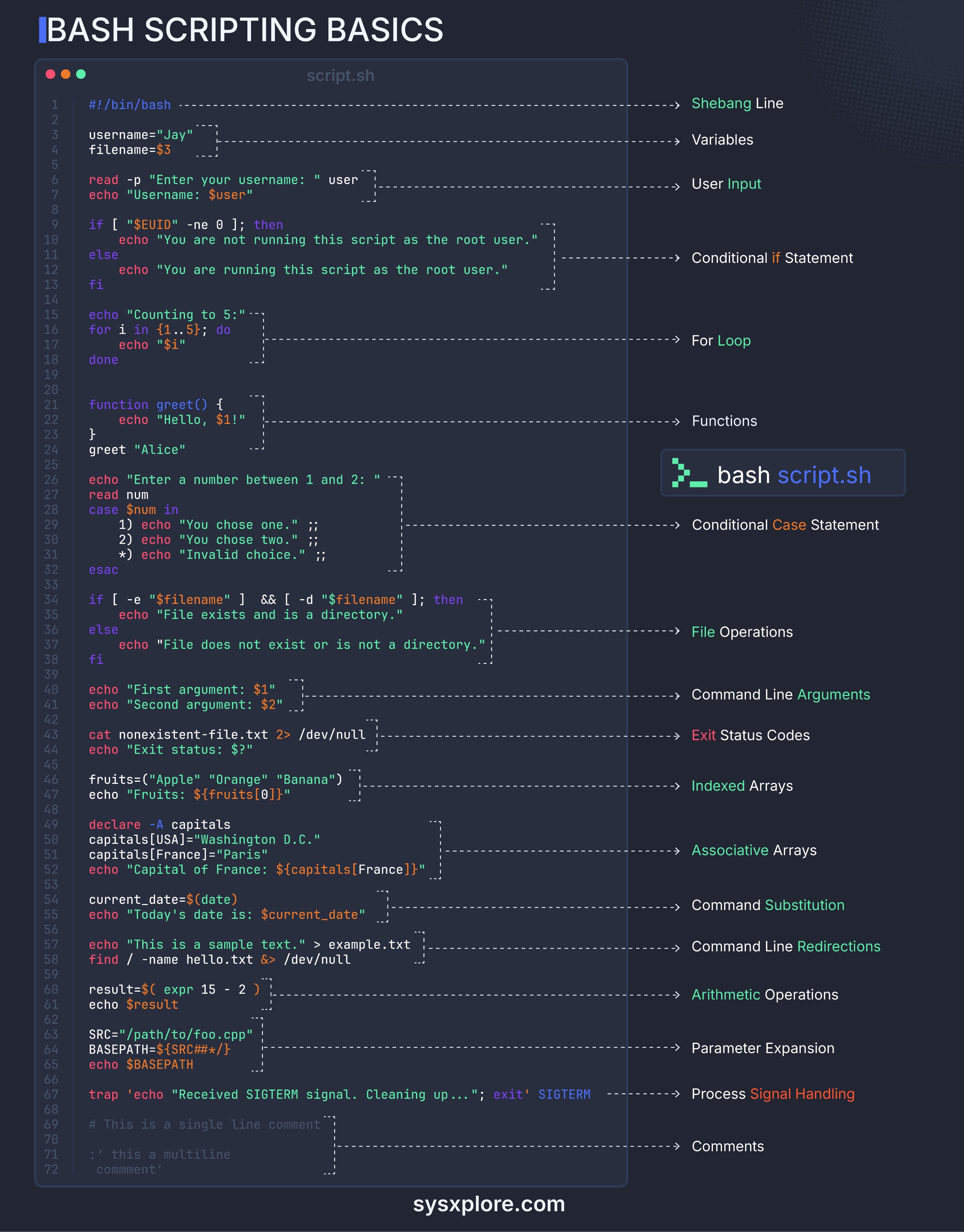
1. 基础概念
Shell 是一个命令行解释器,它允许你运行程序、提供输入,并以半结构化的方式查看输出。几乎所有的计算机操作系统都以某种形式提供了 Shell,目前最广泛使用的 Shell 是 Bourne Again SHell,简称 BASH。
1
2
| missing:~$ date
Fri 10 Jan 2020 11:49:31 AM EST
|
上面是 BASH 的主要文本界面。它告诉你当前所在的计算机是 missing,而当前工作目录(即目前所在的位置)是~(表示“home”目录的缩写)。$符号表示你不是 root 用户(root 用户用#符号表示)。在这个提示符下,你可以输入命令date,Shell 会对其进行解释并执行。
Shell 基本命令与操作
文件操作命令
ls:列出目录内容,ls -l 列出详细信息,ls -a 列出隐藏文件cd:切换目录,cd .. 返回上一级目录,cd ~ 返回主目录pwd:显示当前目录mkdir:创建目录,mkdir -p 创建多级目录touch:创建文件,如果文件存在,则更新文件的访问和修改时间rm:删除文件或目录,rm -r 删除目录及其内容,rm -f 强制删除cp:复制文件或目录,cp -r 复制目录及其内容mv:移动文件或目录,mv -i 移动文件时提示cat:显示文件内容,cat -n 显示行号grep:搜索文件内容,grep -r 搜索目录及其内容find:查找文件,find -name 查找文件名,find -type 查找文件类型chmod:修改文件权限,chmod 755 设置文件权限为 755chown:修改文件所有者,chown newuser:newgroup 修改文件所有者和所属组tar:压缩和解压文件,tar -czvf 压缩文件,tar -xzvf 解压文件
进程管理
ps:显示进程状态kill:终止进程killall:终止指定名称的所有进程top:显示系统进程状态
| 命令 | 功能描述 | 常用参数示例 |
|---|
cd | 切换目录 | cd ~/projects |
ls | 列出目录内容 | ls -la |
pwd | 显示当前工作目录 | pwd |
echo | 输出文本/变量 | echo $PATH |
which | 显示命令的完整路径 | which python |
cat | 查看/拼接文件内容 | cat file1 file2 |
cp | 复制文件/目录 | cp -r dir1 dir2 |
mv | 移动/重命名文件 | mv old.txt new.txt |
rm | 删除文件 | rm -rf directory |
mkdir | 创建目录 | mkdir -p path/to/dir |
touch | 创建空文件/更新时间戳 | touch newfile |
tee | 创建空文件/更新时间戳 | touch newfile |
常用工具
grep:文本内容检索,用于搜索匹配的行,支持基本正则(grep) 和扩展正则 (grep -E)sed:基于行的文本编辑器,用于替换、删除、插入文本,支持基本正则(-E)awk:基于列的文本分析工具,支持正则匹配,用于数据筛选、统计等find:文件搜索tar/zip:压缩解压less:分页查看文件内容wc:统计行数、单词数和字节数sort:排序uniq:清除重复数据,需要在排序后使用paste:将多行输入数据拼接成单行(-s),并用特定的分隔符分割(-d,)bc:命令行计算器,支持文本输入(使用 echo 等)xargs:将多行文本转换成后续命令的输入参数,在查找文件并进行后续操作时非常有用。ffmpeg:对图像和视频数据进行处理head, tail:显示输入数据的首/尾数据,可指定显示的行数(-n10)
输入输出重定向
1
2
3
4
5
6
7
8
9
10
| # 标准输出重定向
ls > output.txt # 覆盖写入
ls >> output.txt # 追加写入
# 标准错误重定向
ls 2> error.log
ls 2>&1 # 合并标准输出和错误
# 输入重定向
echo < input.txt
|
通配符(Globbing)
通配符用于匹配文件名或路径,常用于 ls、cp、mv、rm 等命令中,这些通配符在 bash 脚本和命令行中都很常用,可以结合 grep、find、sed 等工具提高效率。主要的通配符有:
* 匹配任意数量的字符(包括空字符)? 仅匹配一个任意字符(但不能是空)[] 只匹配[]内的一个字符,[^]表示匹配非括号内的字符。{} 用逗号分隔多个模式,匹配其中任何一个(Bash 扩展)。
1
2
3
4
5
6
7
| ls *.txt # 匹配所有 .txt 结尾的文件
ls a* # 匹配所有以 "a" 开头的文件
ls ?.txt # 匹配单个字符+.txt的文件,如 a.txt、b.txt
ls file[123].txt # 匹配 file1.txt、file2.txt、file3.txt
ls file[a-c].txt # 匹配 filea.txt、fileb.txt、filec.txt
ls file[^1].txt # 匹配 file2.txt、file3.txt,但不匹配 file1.txt
mv {file1,file2}.txt backup/ # 移动 file1.txt 和 file2.txt 到 backup/
|
扩展通配符 extglob, globstar
extglob 是 Bash 的一个可选特性,默认是关闭的。启用后,支持更强大的通配符匹配(类正则匹配):
| 模式 | 作用 |
|---|
| ?(pattern) | 匹配 0 或 1 次 pattern |
| *(pattern) | 匹配 0 或 多次 pattern |
| +(pattern) | 匹配 1 次 或 多次 pattern |
| @(pattern) | 匹配 1 次 pattern(类似 {}) |
| !(pattern) | 匹配非 pattern(相当于反向匹配) |
1
2
3
4
5
6
7
8
| shopt -s extglob # 开启扩展通配符
shopt -u extglob # 关闭扩展通配符
ls file?(1).txt # 匹配 file.txt 或 file1.txt
ls file*(1).txt # 匹配 file.txt、file1.txt、file11.txt、file111.txt ...
ls file+(1).txt # 仅匹配 file1.txt、file11.txt(至少要有 1 个 "1")
ls file@(1|2).txt # 只匹配 file1.txt 或 file2.txt
ls !(*.txt) # 列出非 .txt 文件
|
globstar 也是 Bash 的一个可选特性,启用后,通配符**可以匹配递归的目录(包括子目录中的所有文件)。默认情况下,**只能匹配当前目录。
1
2
| shopt -s globstar # 启用 globstar
ls **/*.txt # 列出所有子目录中的 .txt 文件
|
结合上面提到的通配符(globbing)和常用工具如 grep、find、sed 等可以大大提高日常工作效率。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| # 结合 rm 进行文件删除
rm -v !(*.c|*.h) # 删除所有非 `.c` 或 `.h` 结尾的文件
# 结合 tar 进行备份
tar -cvf backup.tar !(backup.tar|*.tmp) # 备份所有文件,排除 backup.tar 和 .tmp 文件
# 结合 grep 进行文件内容搜索
grep "ERROR" *.log # 在所有 .log 文件中查找包含 "ERROR" 的行
grep -r "TODO" src/ # 递归查找 src 目录下所有文件中包含 "TODO" 的行
# 结合 find 进行文件筛选
find . -name "*.log" # 查找当前目录和子目录下所有 .log 文件
find . -name "file[1-5].txt" # 匹配 file1.txt, file2.txt ... file5.txt
# find + grep 过滤文件内容
find . -name "*.sh" -exec grep "function" {} + # 查找所有 .sh 文件中包含 "function" 的行
find . -type f ! -name "*.txt" -exec grep "hello" {} + # 查找非 .txt 文件中的 "hello"
# 结合 sed 进行文本批量替换
sed -i 's/foo/bar/g' *.txt # 将所有 .txt 文件中的 "foo" 替换为 "bar"
find . -name "*.html" -exec sed -i 's/oldtext/newtext/g' {} + # 查找所有 .html 文件,并将文件中的"oldtext"替换为"newtext"
# 结合 awk 处理匹配到的内容
grep "ERROR" *.log | awk '{count++} END {print "Total Errors:", count}'
|
正则表达式
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| grep '^[A-Z]' file.txt # 以大写字母开头的行
grep "gr[ae]y" file.txt # 匹配 "gray" 或 "grey"的行
grep -E "o{2,4}" file.txt # 匹配 "o" 出现 2~4 次,如 "oo", "ooo", "oooo"
sed 's/foo/bar/' file.txt # 只替换每行第一个 "foo"
sed 's/foo/bar/g' file.txt # 替换所有 "foo"
sed '/^#/d' file.txt # 删除以 "#" 开头的注释行
sed -n '/error/p' logfile # 打印含 error 的行
awk '/error/ {print}' file.txt # 只打印包含 "error" 的行
awk '{ if (match($0, /[0-9]+/)) print substr($0, RSTART, RLENGTH) }' file.txt # 提取每行的第一个数字
find . -regex ".*\.log" # 查找所有 ".log" 结尾的文件
find . -type f -regex ".*/[0-9]{4}-[0-9]{2}-[0-9]{2}\.txt" # 查找日期格式 (YYYY-MM-DD.txt) 的文件
# 扩展正则,等价于 grep -E,支持 +、|、? 语法。
egrep "error|warning" file.txt # 查找 "error" 或 "warning"
|
管道 piping
1
2
3
4
5
6
7
8
9
10
| # 基本管道
ls -l | grep ".txt"
# 多级管道
cat access.log | grep "404" | awk '{print $7}' | sort | uniq -c
# 命名管道
mkfifo mypipe
ls -l > mypipe &
cat < mypipe
|
进程管理
1
2
3
4
5
6
7
8
9
10
11
12
13
| # 后台运行
long_process &
# 作业控制
jobs # 查看后台作业
fg %1 # 切换到前台
bg %2 # 继续后台运行
# 信号处理
trap 'cleanup' SIGINT # 捕获 Ctrl+C
# 超时控制
timeout 5s slow_command
|
2. 脚本编程 Script
Cheatsheet
变量操作
1
2
3
4
5
| name="John" # 变量定义
echo $name # 变量使用
# 环境变量
export PATH="$PATH:/my/custom/path"
|
一些常见的特殊变量:
$$ 当前进程 ID$? 上条命令退出码,0 为成功,1 为失败$0 脚本名称$1 ~ $9 脚本的 9 个输入参数$# 参数数量$@ 所有参数的集合,一般用于遍历$_ 上条命令的最后一个参数
命令替换
通过$()可以把括号内命令的执行结果作为变量进行后续处理
1
| echo "we are in $(pwd)"
|
条件判断
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| # 数值比较
if [ "$a" -gt "$b" ]; then
echo "a > b"
fi
# 字符串比较
if [ "$str1" = "$str2" ]; then
echo "Strings are equal"
fi
# 文件测试
if [ -f "/path/to/file" ]; then
echo "File exists"
fi
# 使用正则表达式进行条件判断
if [[ "hello123" =~ ^hello[0-9]+$ ]]; then
echo "匹配成功"
fi
|
循环结构
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| # For 循环
for i in {1..5}; do
echo "Number $i"
done
# While 循环
count=0
while [ $count -lt 5 ]; do
echo $count
((count++))
done
# 遍历文件
for file in *.txt; do
echo "Processing $file"
done
|
函数定义
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| # 简单函数
greet() {
echo "Hello, $1!"
}
greet "Alice"
# 返回值处理
get_random() {
local max=$1
return $((RANDOM % max))
}
get_random 100
echo "Random number: $?"
|
shebang #!
在文件的首行可以定义 shebang 语句,用于告诉 Shell 如何执行这个文件。例如,我们想要执行下面的 Python 脚本:
1
2
3
4
5
| #!/usr/local/bin/python
import sys
for arg in reversed(sys.argv[1:]):
print(arg)
|
我们可以使用下面两种方式来运行 test.py 文件:
1
2
3
4
5
| # 不使用shebang语句
python ./test.py a b c
# 使用shebang语句
./test.py a b c
|
3. CLI 开发环境
job control
1
2
3
4
5
6
7
8
9
10
11
12
| # 后台运行一个进程&
nohup sleep 100 &
# 打印当前正在运行的进程
jobs
# 使用快捷键Ctrl+z可以暂停进程,使用下面命令继续执行进程
bg %1
# 暂停或消灭进程
kill -STOP %1
kill -KILL %1
|
dotfile
CLI 使用 dotfile 来对其进行配置,可以把配置文件集中保存,通过 git 进行管理,然后连接(symlink)到 home 目录下。
1
| ln -s path/to/file sysmlink
|
相比于直接读 man 文档,更好的学习方法是在 GitHub 中搜索 dotfiles,然后从其他人分享的配置文件中学习。
4. 现代工具链
增强工具
| 传统工具 | 现代替代 | 特性 |
|---|
| ls | exa | 图标支持/元数据显示 |
| cat | bat | 语法高亮/分页器集成 |
| find | fd | 更快的搜索速度,语法高亮 |
| grep | ripgrep(rg) | 多线程搜索,带上下文检索 |
| man | tldr | 简化版命令手册 |
| grep | fzf | 可交互式搜索 |
1
2
3
4
5
| # 搜索scratch文件夹下导入requests库的py文件,并且输出检索结果的上下5行作为上下文。
rg "import requests" -t py -C 5 ~/scratch
# 搜索首行没有shebang语句的sh文件,-u表示不要忽略以.开头的隐藏文件
rg -u --files-without-match "^#\!" -t sh
|
实用工具:
zsh-history-substring-search:历史命令动态补全,目前还没有配置成功。broot:可交互式快速查找文件并打开tmux:多终端窗口管理工具
5. 最佳实践
- 使用版本控制管理配置文件
~/.bashrc, ~/.zshrc - 为常用操作创建别名
alias ll="ls -lah" - 保持命令可读性(合理换行)
- 环境变量:
PATH, HOME, EDITOR 等 - 使用 shellcheck 查看脚本是否有语法错误
- 检验正则表达式是否正确的小技巧:利用一些便捷的网络工具
常用快捷键
| 快捷键 | 功能 |
|---|
| Ctrl+C | 中断当前运行的程序 |
| Ctrl+D | 退出当前 shell 或输入 EOF |
| Ctrl+Z | 将当前程序放到后台运行 |
| Ctrl + A | 将光标移动到行首 |
| Ctrl + E | 将光标移动到行尾 |
| Ctrl + U | 删除光标前的所有内容 |
| Ctrl + K | 删除光标后的所有内容 |
| Ctrl + W | 删除光标前的一个单词 |
| Ctrl + R | 搜索历史命令 |
| Ctrl+G | 退出历史命令搜索模式 |
| Ctrl+L | 清屏,相当于 clear 命令 |
| Alt + . | 插入上条命令最后一个参数 |