SWE@Google
Software Engineering at Google 的中文译本。
作者通过 github 制作的电子书网站很精美,自己也可以抽空学习一下怎么制作。
本书强调了三个基本原则,我们认为软件组织在设计、架构和编写代码时应该牢记这些原则:
- Time and Change:How code will need to adapt over the length of its life
- Scale and Growth:How an organization will need to adapt as it evolves
- Trade-offs and Costs:How an organization makes decisions, based on the lessons of Time and Change and Scale and Growth
本书的主题分为谷歌软件工程领域的三个主要方面:
- Culture:the development of software is a team effort
- Processes:complete stress test for developing best practices.
- Tools:tooling infrastructure to provide benefits to our codebase as it both grows and ages
软件工程是什么
程序设计与软件工程的区别
编程,或者说程序设计和软件工程之间有三个关键的区别:时间、规模和权衡取舍。
在一个软件工程项目中,工程师需要更多关注时间成本和需求的变化;需要更加关注规模和效率,无论是对我们生产的软件,还是对生产软件的组织;需要做出更复杂的决策,其结果风险更大,而且往往是基于对时间和规模增长的不确定性的预估。
Software engineering is programming integrated over time.
编程是软件工程的一个重要部分:毕竟,生成任何新软件都需要从编程开始,但我们也需要在编程任务(开发)和软件工程任务(开发、修正、维护)之间进行划分。
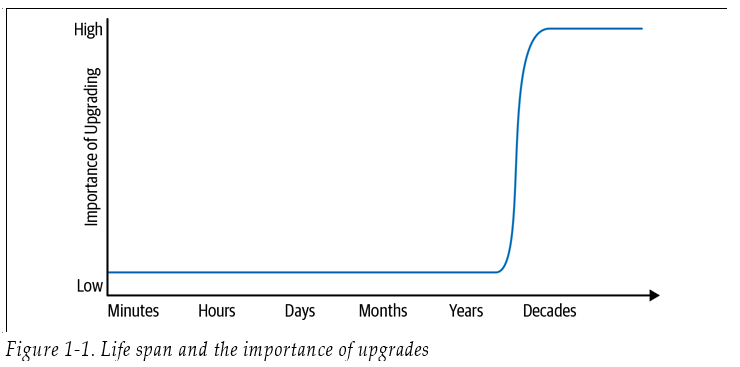
时间的增加为编程扩展了一个重要的新维度。了解时间对编程的影响的一种方法是思考:代码的预期生命周期是多少?以生命周期只有几分钟的代码和将持续运行几十年的代码作为对比,他们之间在时间维度上的数量级相差 1 万倍:
这里的生命周期不是指“开发生命周期”,而是指“维护生命周期”——代码将持续构建、执行和维护多长时间?这个软件能提供多长时间的价值?
通常,周期短的代码不受时间的影响。对于一个只需要存活一个小时的程序,你不太可能考虑其底层库、操作系统、硬件或语言版本的更新。这些短期程序实际上只是一个编程问题,就像在一个压缩得足够扁的立方体是正方形一样。随着我们扩大时间维度,允许更长的生命周期,变化显得更加重要。在十年或更长的时间里,大多数程序的依赖关系,无论是隐式的还是显式的,都可能发生变化。
这一认识是我们区分软件工程和编程的根本原因,同时也是我们所说的软件可持续性的核心。如果在预期生命周期内,软件能够对任何有价值的变化做出反应,无论是技术还是商业原因,那么这个软件就是可持续的。
另一种看待软件工程的方法是考虑规模。有多少人参与到软件工程中?随着时间的推移,他们在开发和维护中扮演什么角色?编程通常是个人的创造行为,但软件工程是团队的工作。早期的软件工程定义为这一观点提供了一个很好的角度:由多人开发的多版本程序。这表明软件工程和编程之间的区别是时间和人力的区别。团队协作带来了新的问题,但也提供了比单个程序员更大的潜力,进而产生更有价值的系统。
由于时间和规模的增加,软件工程需要做出的决策的复杂性及其风险也在增加。在软件工程中,我们经常被迫在多种路径之间进行 trade-off,有时这些选择的影响重大,并且我们通常还要面对不完善的价值衡量标准。软件工程师的工作目标是实现组织、产品和开发工作流程的可持续性并控制成本。在这些因素的基础之上,评估有哪些 trade-off 并做出理性的决定。有时,我们可能会推迟维护更改,甚至接受扩展性不好的策略,同时明白我们需要在将来重新审视这些决策。
Time and Change 时间与变化
当一个新手学习编程时,其代码的生命周期通常以小时或天为单位来衡量。编程作业和练习往往是一次性编写的,几乎不需要重构,更不用说长期维护了。这些程序通常在最初完成后就不会再被重新构建或执行。在教育环境中,这并不令人惊讶。如果涉及到一些比较复杂的项目,这些开发者可能需要根据需求的变化,对一些代码进行重构,但他们不太可能被要求处理软件开发环境的变化。
我们也可以在常见的行业环境中发现短生命周期代码的开发者。
- 移动应用程序的生命周期通常很短暂,并且完全重写代码的情况相对常见。
- 初创公司的工程师可能会选择专注于眼前的目标,而不是长期投资,因为公司可能活不到足以享受那些慢慢见效的基础设施投资收益的时间。一个连续创业的开发者可能有 10 年的开发经验,但几乎没有维护任何预期存在超过一两年软件的经验。
另一方面,一些成功的项目实际上拥有无限的生命周期:我们无法合理预测 Google 搜索、Linux 内核或 Apache HTTP 服务器项目的终点。对于大多数 Google 项目,我们必须假设它们将无限期地存在——我们无法预测什么时候不再需要升级依赖项、语言版本等。随着这些项目生命周期的延长,它们最终会与编程作业或初创公司开发产生不同的感觉。
Hyrum’s Law 海勒姆定律
With a sufficient number of users of an API, it does not matter what you promise in the contract: all observable behaviors of your system will be depended on by somebody.
Hyrum 定律代表了一种实际知识,即使有最好的意图、最好的工程师和扎实的代码审查实践也难以提前预防所有可能的后果。作为 API 所有者,你通过明确接口承诺会获得一定的灵活性和自由度,但实际上,一个给定变更的复杂性和难度也取决于用户发现你的 API 某些可观察行为的有用性。如果用户不能依赖这些行为,你的 API 将很容易改变。给定足够的时间和足够多的用户,即使是最无害的变更也会破坏某些东西。
Scale and Efficiency 规模和效率
你的组织生产和维护代码所依赖的一切都应该在总体成本和资源消耗方面具有可扩展性。
Policies That Don’t Scale 不可扩展的策略
只要稍加练习,就可以很容易地发现不可扩展的策略。最常见的情况是,可以通过考虑施加在单个设计并想象组织规模扩大 10 倍或 100 倍。当我们的规模增大 10 倍时,我们会增加 10 倍的工作量,而我们的工程师能跟得上吗?我们的工程师的工作量是否随着组织的规模而增长?工作是否随着代码库的大小而变多?如果这两种情况都是真实的,我们是否有机制来自动化或优化这项工作?如果没有,我们就有扩展问题。
在 2012 年,我们试图通过降低流失规则来阻止这种情况:基础架构团队必须将内部用户迁移到新版本,或者以向后兼容的方式进行更新。我们称之为流失规则的这一策略具有更好的扩展性:依赖项目不再为了跟上进度而花费更多的精力。
我们还了解到,有一个专门的专家组来执行变更规模比要求每个用户付出更多的维护工作要好:专家们花一些时间深入学习整个问题,然后将专业知识应用到每个子问题上。迫使用户对流失作出反应意味着每个受影响的团队做了更糟糕的工作,解决了他们眼前的问题,然后扔掉了那些对现在无效的知识。Expertise scales better.
Policies That Scale Well 规模化策略
我们最喜欢的内部策略之一是为基础架构团队提供强大的支持,维护他们安全地进行基础措施更改的能力。如果一个产品由于基础架构更改而出现停机或其他问题,但我们的持续集成(CI)系统中的测试没有发现问题,这不是基础架构变更的错。
更通俗地说,如果你喜欢它,你应该对它进行 CI 测试(If you liked it, you should have put a CI test on it),我们称之为碧昂斯规则。
If you liked it then you shoulda put a ring on it.
—Single Ladies,Beyoncé
从规模化的角度来看,碧昂斯规则意味着不是由我们的通用 CI 系统触发的、复杂的、一次性的定制测试不能被认为是有效的测试。如果没有这一点,基础架构团队的工程师需要跟踪每个受影响的代码团队,询问他们是如何进行测试的。当仅有一百个工程师的时候,我们可以这样做,但是当工程师数量庞大时,我们绝对不能这样做。
Trade-offs and Costs 权衡和成本
如果我们理解如何编程,理解我们正在维护的软件的生命周期,并且理解如何在更多工程师生产和维护新功能时进行规模化维护,那么剩下的就是做出好的决策。
在软件工程中,就像在生活中一样,好的选择会带来好的结果。然而,这种观察的影响很容易被忽视。在谷歌内部,对于because I said so有强烈的反感。重要的是,任何议题都要有一个决策者,当决策是错误的时候,要有明确的改进路径。并且每件事都需要一个明确的理由。
I don’t agree with your metrics/valuation, but I see how you can come to that conclusion.的情况是完全可以接受的。
而just because、because I said so、because everyone else does it this way则常常是糟糕决策潜伏的地方。
当我们在选择两种工程方案时,需要能够解释清楚general cost是多少并作出合理的选择,如下所示。
- Financial costs (e.g., money)
- Resource costs (e.g., CPU time)
- Personnel costs (e.g., engineering effort)
- Transaction costs (e.g., what does it cost to take action?)
- Opportunity costs (e.g., what does it cost to not take action?)
- Societal costs (e.g., what impact will this choice have on society at large?)
从历史上看,忽视Societal costs的问题非常容易出现。谷歌和其他大型科技公司可以可靠地部署拥有数十亿用户的产品,在许多情况下,这些产品是高净效益的,但当我们以这样的规模运营时,即使在可用性、可访问性和公平性方面或潜在的滥用方面存在微小差异也会被放大,并对边缘化的群体产生不利影响。软件已经渗透到社会和文化的各个方面,因此,明智的做法是,在做出产品和技术决策时,我们要意识到我们所能带来的好处和坏处。
除了上述的成本,还有一些 biases:
- status quo bias(维持现状偏差):个体在决策时,倾向于不作为、维持当前的或者以前的决策的一种现象。这一定义揭示个体在决策时偏好事件当前的状态,而且不愿意采取行动来改变这一状态,当面对一系列决策选项时,倾向于选择现状选项
- loss aversion(损失厌恶偏差):人们面对同样的损失和收益时感到损失对情绪影响更大。
当我们评估成本时,我们需要牢记之前列出的所有成本:一个组织的健康不仅仅是银行里是否有钱,还包括其成员是否感到有价值和有成就感。在软件开发等高度创新和利润丰厚的领域中,财务成本通常不是限制因素,人力资源才是,因此,保持工程师快乐、专注和参与所带来的效率提升会成为主导因素。
我们的目标是对我们所做的每件事都有同样程度的关注和明确的成本/收益权衡,从办公用品和员工津贴到开发者的日常体验,再到如何提供和运行全球规模的服务。我们经常说,谷歌是一家数据驱动的公司。实际上,这是一种简化:即使没有数据,也会有证据、先例和论据。做出好的工程决策就是权衡所有可用的输入,并就权衡做出明智的决策。这些决策基于直觉或公认的最佳实践,但这只会发生在我们已经耗尽了尝试测量或估计真正潜在成本的方法之后。
最后,工程团队的决策应该归结为一下几种情况:
- We are doing this because we must (legal requirements, customer requirements).
- We are doing this because it is the best option (as determined by some appropriate decider) we can see at the time, based on current evidence.
决策不应该是We are doing this because I said so.