deep dive into LLMs
some key takeaways from Andrej’s awesome video.
Pre-training
step1: download and preprocess the internet
fineWeb: a new, large-scale (15-trillion tokens, 44TB disk space) dataset for LLM pre-training.
How to find the raw data: use a public repository of crawled webpages. like the one maintained by the non-profit CommonCrawl
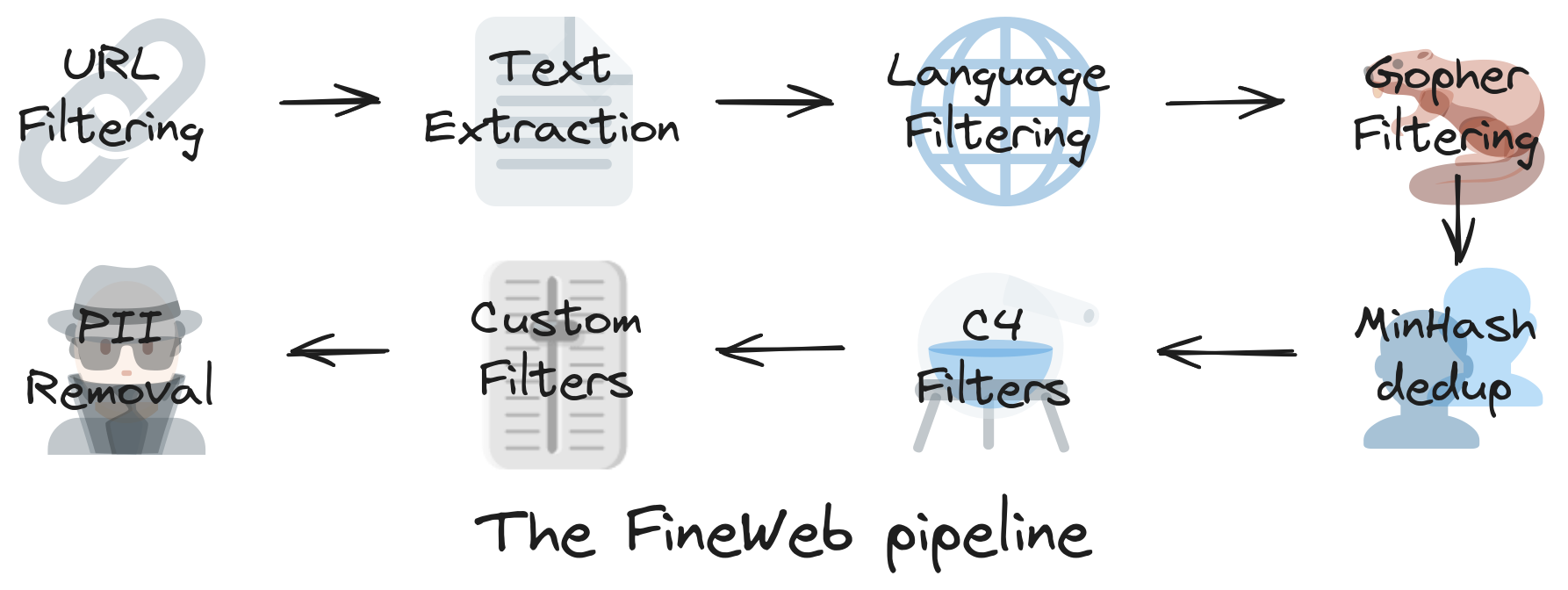
step2: tokenization
Convert between raw text into sequences ot symbols/tokens
example: ~5000 Unicode characters
- ~= 40.000 bits (2 possible tokens)
- ~= 5000 bytes (256 possible tokens)
- ~= 1300 GPT-4 tokens (100.277 possible tokens)
一个在线可交互的 tokenizer:Tiktokenizer
step3: neural network training
给定输入和输出(label),对模型的参数进行训练/拟合,训练完成之后,会得到一组满意的权重(weights),然后便可以进入下一阶段:推理。
step4: inference
根据用户给定的输入,模型会利用训练得到的权重计算出相应的输出,返回给用户。
demo: reproducing OpenAI‘s GPT-2
GPT-2 was published by OpenAl in 2019, in Paper: Language Models are Unsupervised Multitask Learners
GPT-2 is a transformer neural network with:
- 1.6 billion parameters
- maximum context length of 1024 tokens
- trained on about 100 billion tokens
My reproduction: llm.c, training cost is about 1day/$672.
Why training cost drops so quickly?
- dataset has gotten much better
- computers have gotten much faster
- software has gotten much efficient
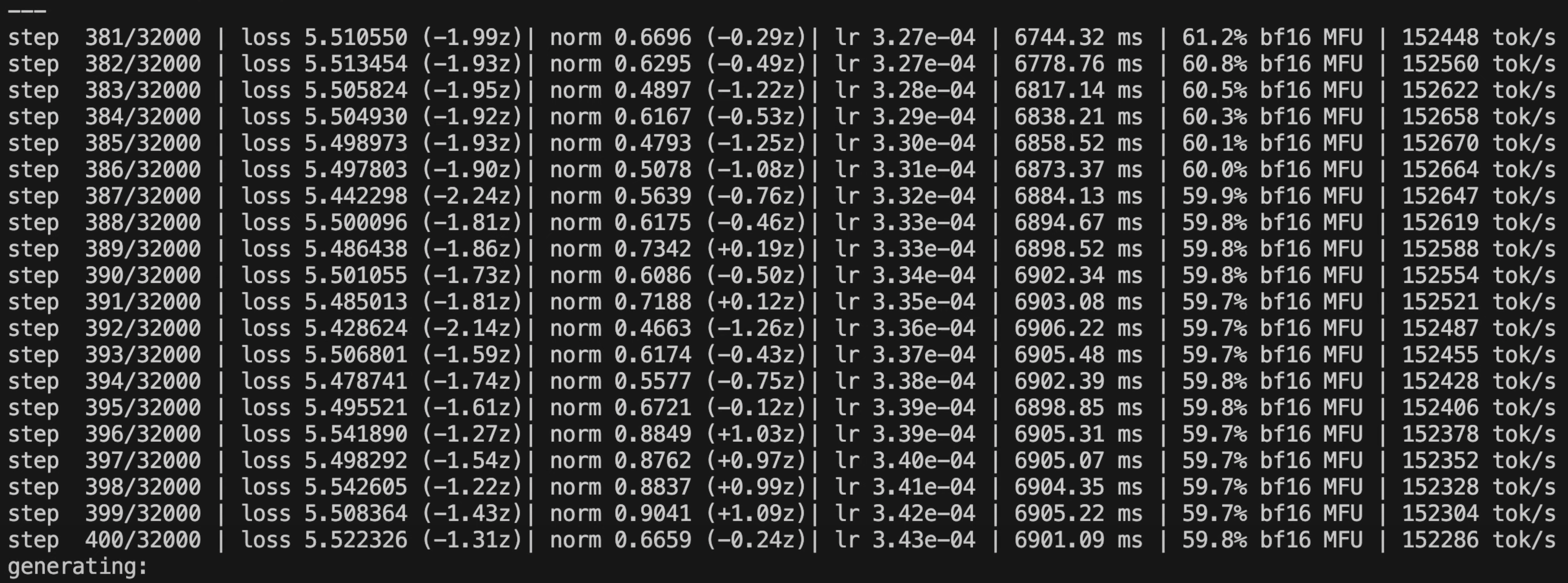
截图中的每一行代表一次模型的参数更新,每一次更新会从 dataset 中提取1m token作为输入,时长大约为 7s,总共需完成 32000 次更新。可以看出,随着参数更新的进行,模型的损失在逐渐降低。完成 20 次更新后,模型会进行一次推理,用于检验模型的生成效果。
训练硬件分析:
- 训练平台:lambda
- 训练硬件:8xH100 node
base model release
大的科技公司会定期公开他们训练好的基础模型,如下表所示:
| 名称 | 公司 | 发布日期 |
|---|---|---|
| GPT-2 1.6B | openAI | 2019 |
| llama3 405B | meta | 2024 |
以openAI GPT-2为例,公开的内容通常包括
- model.py:用于描述模型结构的 python 代码
- 模型权重
基础模型一般不带有问答功能,只会根据输入预测接下来的 token 是什么,相当于一个网络文本模拟器(internet document simulator)。由于其内在的概率模型输出机制,即使输入相同的提示词,每次得到的回复都是不一样的。
带有 Instruct 后缀的基础模型可以直接作为问答助手来使用。
使用Hyperbolic对基础模型进行简单测试。
Post-training: SFT
Supervised fine-tuning 的目的是在 base model 的基础上得到一个有实用价值的 assistant,使用 conversation example(问答实例)而不是代码进行“编程”。SFT 的流程和 Pre-training 完全一致,只是两者使用的训练数据集不一样,SFT 使用更小的问答数据集,因此训练时间也更短,通常只需要几个小时或几天即可。
如何使用 conversation 数据对模型进行微调? 类比 TCP/IP 中的数据包(包含表头和数据)的概念,按照一定的规则对 conversation 进行编码,然后再将进行 tokenization,如下所示:
原始对话为:
1
2
3
4
what is 2+2?
2+2=4
what if It was *?
2*2=4, same as 2+2!
进行编码后的对话为:
1
2
3
4
5
<|im_start|>user<|im_sep|>what is 2+2? <|im_end|>
<|im_start|>assistant<|im_sep|>2+2=4<|im_end|>
<|im_start|>user<|im_sep|>what if It was *?<|im_end|>
<|im_start|>assistant<|im_sep|>2*2=4, same as 2+2!<|im_end|>
<|im_start|>assistant<|im_sep|>
tokenization 之后为:
1
2
3
4
5
200264, 1428, 200266, 13347, 382, 220, 17, 10, 17, 30, 220, 200265,
200264, 173781, 200266, 17, 10, 17, 28, 19, 200265,
200264, 1428, 200266, 13347, 538, 1225, 673, 425, 30, 200265,
200264, 173781, 200266, 17, 9, 17, 28, 19, 11, 2684, 472, 220, 17, 10, 17, 0, 200265,
200264, 173781, 200266
2022 年 openAI 发布了关于模型微调的经典论文:Training language models to follow instructions with human feedback。openAI 并没有公布其用于模型微调的对话数据集,但是在网上可以找到一些开源的对话数据集,比如OpenAssistant。
在最近的研究中,我们不再依赖人工生成的对话数据集,而是利用已有的 LLM 来自动生成这些对话数据集,用于新模型的微调,例如UltraChat。
key takeaway
when you are talking with ChatGPT, you don’t get those simultaneous answers from a magic AI, but from a group of highly educated experts hired by openAI.
ChatGPT is a statistical simulation of a human labeler
Hallucinations
在huggingface/inference-playground中,如果使用一些较老的模型,比如falcon-7b-instruct,当被问及一些杜撰的问题时,我们会发现模型在编造一些回答(Hallucination),例如:
who is Orson Kovacs?
Orson Kovacs is a fictional character in the 1956 science fiction novel “The Space Merchants” by Frederic Brown. The character is a space trader who deals with interplanetary commerce and politics.
Mitigation 1: knowledge-based refusal
在 meta 2024 年发表的一项研究中The Llama 3 Herd of Models,他们在训练数据集里添加了一些模型不知道的问题,并告诉模型这些问题的正确的答案是不知道。通过这一训练(model interrogation),模型学会了如何判断自己的知识边界,并能够正确回答自己不知道的问题,而不是编撰一些虚构的答案(Hallucination),例如:
who is Orson Kovacs?
I’m sorry, I don’t believe I know.
Mitigation 2:allow the model to search
如何训练模型掌握联网搜索能力,和上面的逻辑类似,想要模型掌握某种能力,就通过例子(example)让它去学习这种能力。这其实是一种和传统软件开发完全不同的思考逻辑,在传统的软件开发流程中,需要新场景新需求时,需要经验丰富的程序员去设计算法和逻辑来解决需求。但是对于 LLM 而言,我们不需要关注模型是如何解决问题的,而只需要准备足够多的案例,告诉它我们想要怎样的结果,LLM 会自己学会解决问题的逻辑。
因此,我们需要构建一个联网搜索的问答数据集,例如:
Human: “Who is Orson Kovacs?”
Assistant: “
Who is Orson Kovacs? [...] Orson Kovacs appears to be ..."
- Knowledge in the parameters == Vague recollection (e.g. of something you read 1 month ago)
- Knowledge in the tokens of the context window == Working memory
由于 llm 并不知道自己是通过怎样的方式训练出来的,所以询问 llm 这类问题是没有任何意义的。即使 llm 回复自己是 ChatGPT,并不意味着 llm 在训练过程中采用了 openAI 的数据,因为 openAI 的 chatGPT 在 llm 领域影响力非常大,因此当模型被问及”你是谁”时,会很自然的给出统计学意义上概率最高的答案:”chatGPT made by openAI”
当然开发者可以采取一些手段回避这种情况,例如在 allenai 团队推出的开源模型OLMo2中,开发团队在微调的过程中插入一个硬编码数据集(OLMo 2 Hardcoded (CC-BY-4.0), 240 prompts),显式告诉模型:”I’m OLMo, an open language model developed by AI2”。
另一种常见的手段是通过在最开始插入 system message 的方式,在任何对话开始之前提醒模型一些关键信息。
Other limitations of llm
Models need tokens to think
考虑下面的两个问答,你认为哪个回答能够更好的训练模型的逻辑思维?
Human: “Emily buys 3 apples and 2 oranges. Each orange costs $2. The total cost of all the fruit is $13. What is the cost of apples?”
Assistant1: “The answer is $3. This is because 2 oranges at $2 are $4 total. So the 3 apples cost $9, and therefore each apple is 9/3 = $3”.
Assistant2: “The total cost of the oranges is $4. 13 - 4 = 9, the cost of the 3 apples is $9. 9/3 = 3, so each apple costs $3. The answer is $3”.
正确的答案是第 2 个回答,我们需要牢记 llm 模型的本质是预测下一个 token,因此 llm 需要从左到右读取 token 并进行推理(预测)。在第 1 个回答中,llm 实际上需要先随机猜出答案是 3,然后在论证答案为什么是 3。而第 2 个回答中,模型是按照数学运算一步一步推理出正确答案是 3。
Models can’t count and do spelling check
基于和上面的相同的原因,llm 无法进行有效的计数和拼写检查操作,因为 llm 的输入会被首先转换成 token,在转换成 token 的过程中会丢失一部分原始信息,例如对于单词 Ubiquitous,模型实际看到的是 3 个 token(50668, 5118, 50855),分别对应这个单词的 3 个词根,Ub,iqu,itous。
目前由于计算效率等因素,采用 token 来进行分词仍然是最主流的做法,也许将来会出现字母级或字节级的模型?
同时对于这类问题,模型往往需要在一次预测(forward propagation)中精确给出答案,这也会减低模型的准确性。
Mitigation: use code
在实际过程中,为了避免模型得出错误的答案,一个常用的技巧是告诉 llm 使用工具,即use code。使用代码计算出的结果往往比模型通过一次预测或”心算”得到的结果更可靠。
Post-training: Reinforcement Learning
强化学习实际上也是在模拟人学习的过程。例如当我们在学校学习新的知识时,我们首先会阅读课本上的内容(Pre-training),然后老师会给我们演示一些习题,并详细讲解这些题目的解题思路(SFT),最后我们会尝试自己独立解题,然后对照答案检查我们的解题思路是否正确,通过大量的习题练习,我们学会了新的知识(reinforcement learning)。
RL 的实际流程:
- 模型得到一个问题(prompt)和最终答案
- 模型根据问题给出大量不同的 solutions
- 对比不同 solutions 得到的答案和最终答案,选出其中较好的 solution (optimization)
- 使用选出的 solution 对模型进行训练
DeepSeek R1: Reasoning model
预训练和监督微调目前已经被公认为 llm 训练必不可少的环节,但是对于强化学习,虽然一些大的科技公司在内部已经开始有一些尝试,但是这些公司并没有将其研究成果公开发表,因此大家对强化学习的训练细节并不是很清楚。这也是为什么当 DeepSeek 第一次在网络公开其相关研究成果DeepSeek R1后,能够引起如此巨大的关注度的原因。
Wait, wait. Wait. That’s an aha moment I can flag here.
上面的经典自白出自 DeepSeek-R1-Zero 在解题中的思考过程,通过强化学习,模型可以真正掌握或涌现出思考的能力(CoT),这种在给出具体答复之前的思考过程无法通过 SFT 强加给模型,也无法通过学习人类的标注数据来掌握,而必须由模型自己通过大量的练习来自发生成。
一些常用的 Reasoning model:DeepSeek-R1-Zero, chatGPT o1, Gemini 2.0 Flash Thinking Experimental
另一个经典的强化学习例子是 2017 年的AlphaGO,在其研究论文中,研究者发现,如果只采用 Supervised learning,即让 AI 学习和模拟人类顶级选手是如何下棋的,即使经过长时间的训练,AI 的水平也只能接近于人类顶级选手的水平,而无法超越人类顶级选手。但是利用 Reinforcement learning,AI 的下棋水平便可以超过人类顶级选手。 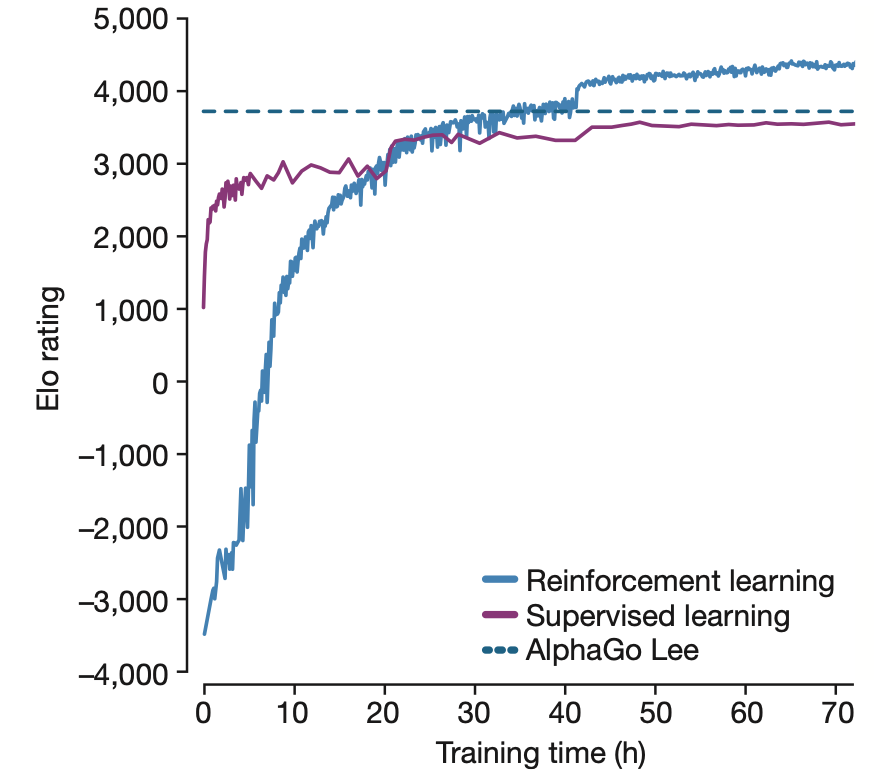
RL-HF: RL in un-verifiable domains
对于一些开放性的问题,我们很难得到一个标准答案或者有一个明确的标准判断答案的好坏,例如下面的问题:
write a joke about pelicans.
在这种场合下,强化学习很难发挥作用,针对这一问题,openAI 在其 2020 年发表的论文Fine-Tuning Language Models from Human Preferences中提出了一种解决方案:Reinforcement learning from Human Feedback,其核心思想如下:
Naive approach:
Run RL as usual, of 1000 updates of 1000 prompts of 1000 roll-outs. (cost. 1,000,000,000 scores from humans!)
RL-HF approach:
- STEP 1: Take 1000 prompts, get 5 roll-outs, order them from best to worst. (cost: 5000 scores from humans)
- STEP 2: Train a neural net simulator of human preferences (“reward model”)
- STEP 3: Run RL as usual, but using the simulator instead of actual humans
RL-HF 的优点
- 允许我们在任意领域(un-verifiable domains)执行强化学习
- 通过”discriminator - generator gap”改善模型的性能。因为在大多数情况下 discriminate 比 generate 更容易,例如对于”Write a poem about winter”这类问题,让 human labeler 写出一首完美符合问题描述的诗比让其判断模型生成的 5 首诗中哪个最好要难得多。
RL-HF 的缺点
RL-HF 只是 a lossy simulation of humans,它并不能完美反映人类的观点,也没有一个真正的大脑来处理所有可能的情况,这会产生很多误导性的结果。
此外,随着训练次数的增加,模型经常会发现 adversarial examples 来欺骗 reward model,例如在训练的前 1000 次更新,模型生成的笑话可能在逐渐变好,但是超过 1000 次之后,模型可能会生成完全无意义的结果但是从 reward model 拿到非常高的评分,比如”the the the the the the the the”,这种 adversarial examples 通常是无穷无尽的,无法通过人为的设置较低的分数来进行改进。
对于 verifiable domains 的问题则不会有这种问题,因为正确答案通常是明确且清晰的,比如数学公式的结果,模型无法找到一种投机取巧的方法来得到正确答案,因此在 verifiable domains,强化学习的训练次数可以无限制增加,而并不会对模型的实际精度造成负面影响。
因此 RL-HF 并不能被看作”真正的”强化学习,因为它的 reward function 是可以被欺骗的(gamed),并且模型无法在如此短的训练时间内产生真正的思考(DeepSeek-R1-Zero 的”Aha moment”),RL-HF 应该被视为另一种 fine-tuning,可以略微改进模型的效果,但是无法让其产生本质性的进步。
总结和未来展望
llm 就像一块瑞士奶酪 🧀,它在大多数情况下品尝起来很美味(give good results),但是也有很多随机分布的洞洞(give dumb results),最好的方法是把它当成一个工具来使用。
未来发展方向
- 多模态 multi-modal,将 llm 扩展到音频,图像,视频领域,和 llm 并没有本质性的区别,只是将其训练的 token 范围进行了扩展。
- tasks -> agents,agents 可以执行时间跨度更长,内容更复杂的任务
- pervasive, invisible,llm 将被集成和整合到越来越多的领域
- test-time training,llm 在完成预训练之后,其权重会被固定,在后续使用过程中是无法更改的,这一点和人类有很大的不同。人的大脑每时每刻都在学习,其内部的神经元不是固定不变的,而是时时刻刻都在更新,未来的 llm 可能也会具有这种特性。
如何跟踪最新的进展和在日常中使用这些 llm
- llm leader board: 实时查看当前性能最好的 llm,点击链接可以跳转到模型的使用界面
- ai news letter: 每天获取最新的 AI 进展
- X/Twitter: follow 一些知名研究者
- together.ai: 提供各种开源模型的 assistant 版本
- hyperbolic: 提供各种开源模型的基础模型
- 使用LMStudio在本地运行 distilled 大模型